Parametrisk bootstrap baserer seg på at data følger vanlige parametriske statistiske fordelinger som for eksempel normalfordeling eller Poissonfordeling. Ikke-parametrisk bootstrap bygger ikke på noen grunnleggende statistisk modell. Bootstrap har fått stor anvendelse innen bioinformatikk (fylogeni, evolusjonært slektskap, mikromatrise-data).
Ved ikke-parametrisk bootstrap tas det prøver fra den empiriske kumulative tetthetsfunksjonen (ecdf) til datasettet.
Bootstraping brukes til å lage replikater av et datasett. Vi resampler data med tilbakeføring, og starter med det originale datasettet som et enkelt eksempel {100,80,99,120,70}
Se nå hva som skjer med dette datasettet når vi lager replikater ved tilfeldig å plukke ut data fra det opprinnelige datasettet, og deretter legge dem tilbake igjen:
100 80 99 120 70 Opprinnelig datasatt
120 80 99 80 99 Resamplet
100 80 100 80 100 Resamplet
99 120 80 120 100 Resamplet
99 120 80 100 99 Resamplet
Med en datamaskin kan man gjøre dette e.g.n=100000 ganger, og man har derved laget seg et nytt omfattende datasett fra det lille utgangsdatasettet.
Gjennomsnittsverdien for det opprinnelige datasettet er 93.8
Vi finner et estimat for gjennomsnitt (forventet verdi E(X)), og 95% konfidensintervall hvor SE er standardfeilen, t er den kritiske tabellverdien for t-fordelingen
\(\text{95% konfidensintervall}= \mu\; \pm\; t\cdot SE\) :
Bootstrap gjennomsnitt 94 og 95% konfidensintervall (95% KI): 85-103.
Det vil si at vi er konfident om at 95% av tilfellene vil havne innenfor intervallet [85-103]
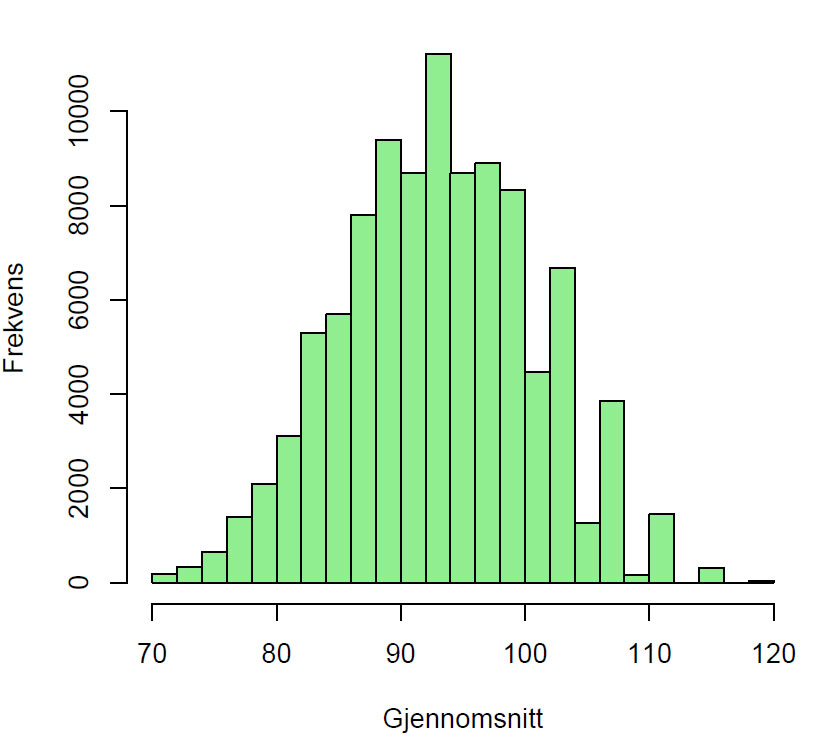
Figuren viser histogram og fordeling av gjennomsnittsverdier for n= 100000 resamplede data fra det originale datasettet.
Bootstrap av en regresjonslinje
Vi kan simulere en linje med normalfordelt variasjon, plotter datapunktene og en regresjonslinje. Deretter kan vi resample data fra både x- og y-verdiene og lage lineære modeller av disse som plottes. Vi ser at variasjonen er minst ved gjennomsnitt av[x,y], vippepunktet som linjen kan dreie omkring.
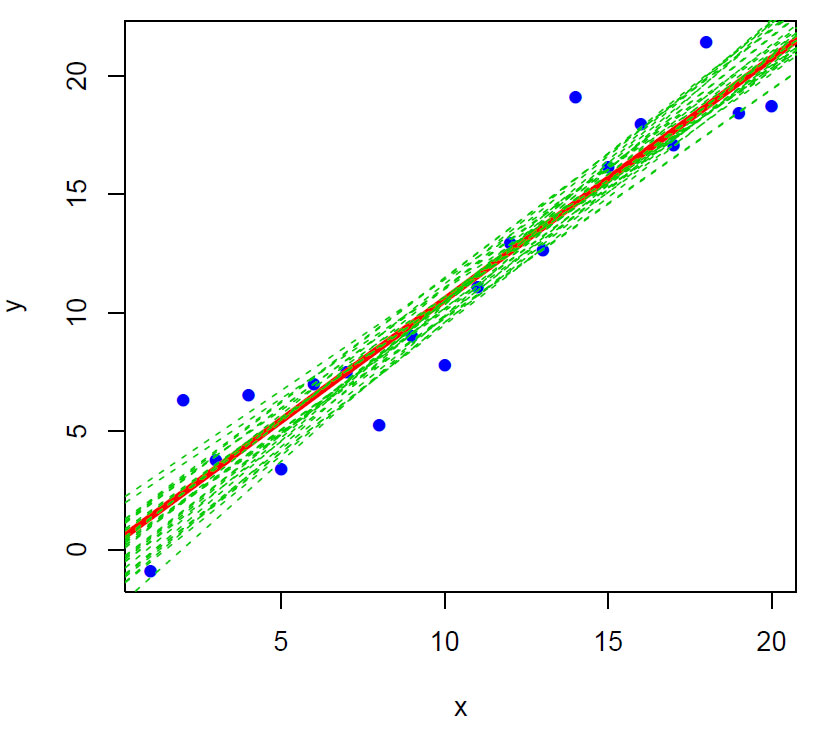
Figur viser simulert datasett med normalfordelt variasjon (blå punkter). Plotter regresjonslinjen (rød). Resmpler datasettet n=30 og lager en lineær modell av hver av dem (prikkete grønne linjer).
R Core Team (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria.
URL https://www.R-project.org/