Om DNA-sekvensering
DNA molekylene våre er bærere av den genetiske informasjon mellom generasjoner, og ”summen” av en enkelt persons DNA molekyler kalles en persons genom og inneholder all arvelig informasjon om denne personen. Grunnenheten i våre DNA molekyler er nukleotider og DNA molekyler er satt sammen av fire ulike nukleotider som forkortes hhv A, C,G og T. Sammensetningen og rekkefølgen av disse fire nukleotidene bestemmer en persons arvelige egenskaper og kan sees på som digital informasjon som forteller mye om hvilke sykdommer man er disponert for og hvilke medisiner og forebyggende tiltak man vil kunne ha glede av. DNA molekylene til enkeltpersoner kan undersøkes ved hjelp av såkalt DNA sekvensering. Dette er en teknikk som har gjennomgått en eksepsjonelt rask utvikling både hva gjelder effektivitet og kostnader, som illustrert i figur 1 og 2.
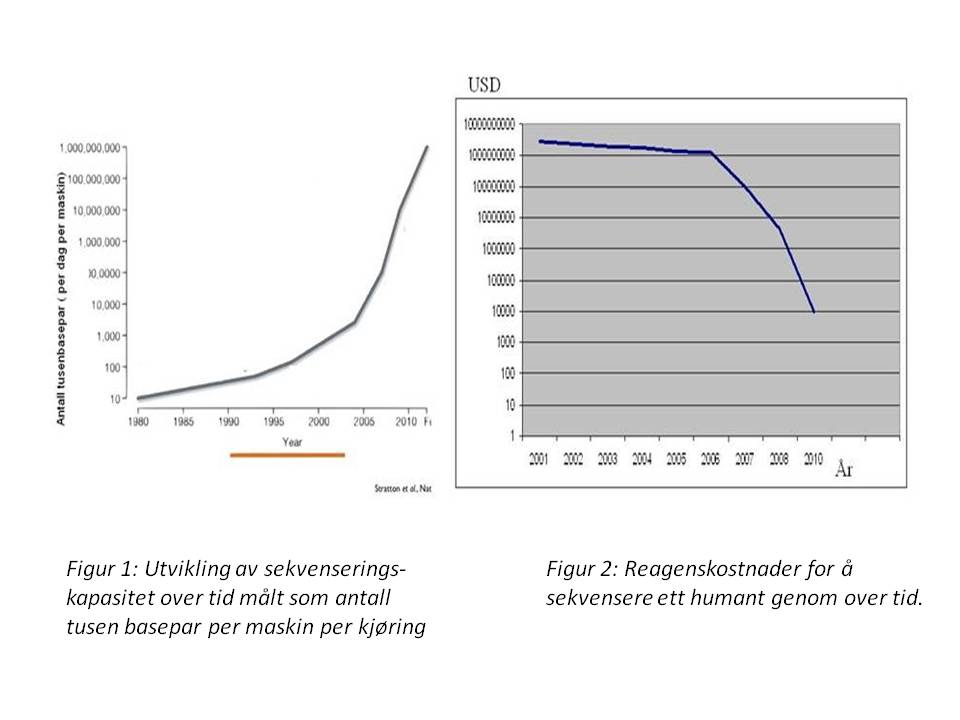
Kartleggingen av det første humane genom som ble sluttført i 2003 kostet 2,8 milliarder USD, mens man i dag kan få gjort det samme for cirka 5000 USD. Enkelte firmaer som jobber med DNA sekvenseringsteknologi hevder at de i løpet av 2-3 år vil ha klar en teknologi som gjør det mulig å sekvensere et helt humant genom for kun 100 USD i reagensutgifter. Dette gjør at det nå er økonomisk overkommelig å sekvensere et stort antall hele genomer i medisinsk diagnostikk og forskning, noe som for kun få år siden var utenkelig. Prosjekter som the Personal Genome project (http://www.personalgenomes.org/) og 10Kuk (http://www.sanger.ac.uk/about/press/2010/100624-uk10k.html) hvor man vil sekvensere hele genomet et stort antall friske personer og pasienter illustrerer dette. Denne typen studier vil føre til en drastisk økning av vår kunnskap om sammenhengen mellom genetisk variasjon og utvikling av sykdom, og i kjølvannet av dette forventer man en markant økning av antall klinisk nyttige gentester.
DNA-sekvensering og utvikling av individualisert medisin
Med individualisert medisin menes medisinsk behandling som er spesielt tilpasset til den enkelte pasient på en helt annen måte enn det som er det vanlige i dagens helsevesen. Utviklingen av individualisert medisin forventes å gi nye og mer effektive behandlingsformer med færre bivirkninger. Genetiske undersøkelser er kanskje den aller viktigste undersøkelsesmetoden for å gjøre medisinsk behandling mer individuelt tilpasset (Lander 2011). Man vet i dag at noen har genetiske varianter som gjør at de bryter ned enkelte medisiner langsomt og derfor bør ha en lavere medisindosering enn andre. Videre er det vist at visse genvarianter disponerer for alvorlige bivirkninger mot spesifikke medisiner, og slike pasienter bør derfor unngå disse medisinene. Andre genvarianter kan fortelle hvilken type medisin som er den riktige for akkurat deg. Kunnskapen om hvordan genvarianter og genfeil har betydning for sykdomsforløp er ikke begrenset til arvelige sykdommer. Det mest velkjente eksempelet på at ervervete (ikke medfødte) genfeil kan si noe om sykdomsårsak, sykdomsforløp, prognose og behandlingsrespons er kreft hvor man kan påvise såkalte somatiske DNA mutasjoner. Hvilke typer mutasjoner man finner i den enkelte svulst kan si noe om prognosen og om hvilke behandlingsformer som kan hjelpe og hvilke som vil gi bivirkninger.
Våre DNA molekyler kan for de fleste formål sees på som uforanderlige i det enkelte individ. (Det forekommer mutasjoner i alle, men disse er sjeldne og for de fleste sykdommer – kreft er det viktigste unntaket – antas disse å ha begrenset betydning). Dette innebærer at genetiske undersøkelser kun trengs å utføres én gang. Dette adskiller genetiske undersøkelser fra de fleste andre diagnostiske medisinske undersøkelser hvor det vanlige er at en undersøkelse tatt som barn forteller lite om helsetilstanden som voksen.
Mot helgenomsekvensering som diagnostisk rutine.
Dagens genetiske undersøkelser er i all hovedsak målrettete mot enkeltgener. Dette innebærer at man ved hjelp av diverse molekylærbiologiske laboratoriemetoder isolerer (egentlig anriker for) de delene av DNA molekylene man er interessert i. Med den raske utviklingen av DNA sekvenseringsteknologien man nå ser, forventes det at dette vil endre seg og at det i flere sammenhenger vil bli lettere og rimeligere å sekvensere hele genomet i stedet for å bruke ressurser på å isolere de deler man er spesielt interessert i. Man ser allerede at de delene av genomet man sekvenserer er vesentlig mer omfattende enn tidligere og i løpet av få år venter vi at helgenomsekvensering blir diagnostisk rutine. Dette innebærer at alle genetiske data vil kartlegges en gang for alle og aktualiserer gjenbruk av dataene gjennom livet etter som ulike helseproblemer dukker opp.
Behovet for å samle og tilgjengeliggjøre gen-data
Samtidig som genomdata representerer et umiddelbart gode for helsetjenesten, representerer det også en kraftig økning i informasjon som klinikere vil måtte forholde seg til, for eksempel ved tolking av undersøkelsesresultater og valg av riktig behandling (Ullman-Cullere 2011). Allerede i dag erkjennes et stort antall sammenhenger mellom kartlagte gener og uventede undersøkelsesresultater eller uvanlige reaksjoner på behandling, og det vil ventelig komme mange tusen flere i årene som kommer. Per i dag er foreligger imidlertid det meste av informasjonen i EPJ i ustrukturert eller ikke standardisert form, slik at klinikeren selv må sjekke opp alle disse sammenhengene. For å sikre at informasjonen fra genomet blir utnyttet effektivt i utredning og behandling, må EPJ opprustes med egnet struktur for klinisk innhold og anvendt kunnskap om de aktuelle sammenhengene.
Juridiske, etiske og teknologiske utfordringer
Genomdata representerer kunnskap om en selv som pasienten ikke nødvendigvis ønsker, for eksempel å vite om høy risiko for dødelige eller uhelbredelige sykdommer senere i livet. Derfor er retten til ikke å vite et viktig premiss i forhold til genetiske undersøkelser, og det å slippe å vite mer om sin genetiske risiko enn det man til enhver tid måtte ønske er et sentralt premiss for norsk lovgining på området. Dette tilsier at opplysninger om genetiske analyseresultater i EPJ må begrenses til det den enkelte pasient til enhver tid måtte ønske. Dagens EPJ har ikke støtte for slik adgangsbegrensning, verken direkte overfor pasienten eller indirekte via helsepersonellet. Adgangsbegrensningen krever støtte både i spesifikk funksjonalitet og generelt i arkitekturen.
Hvorfor en nasjonal løsning?
Genetiske opplysninger, som fremkommet som del av eksisterende diagnostisering, lagres på de enkelte sykehus hjemlet i journalforskriften, og det er ikke noen samlet oversikt over hvilke gentester en person har fått utført. Dette er tilsvarende andre prøver/tester som tas som del av diagnostisering og behandling. Gentestene er heller ikke strukturert på noen konsistent måte. Bedret struktur i elektronisk pasientjournal (EPJ) vil kunne løse noen av utfordringene ved at man vil få en oversikt over analyserte gener i den enkelte EPJ. Dersom Norsk helsenett utvikles til å tilby fellestjenester for norsk helsevesen, vil de være en interessant partner for en nasjonal løsning. Med innføring av helgenomsekvensering vil man imidlertid ha behov for å gi kontrollert tilgang til rådata for å kunne analysere gener etter som nye medisinske problemstillinger dukker opp hos den enkelte pasient, og dette er hverken mulig eller planlagt implementert som en del av dagens EPJ. Dagens infrastruktur hvor genetiske data lagres på ulike helseforetak i landet uten noen samlet oversikt over at slike analyser er gjort vil uvegerlig føre til at analyser dubleres. Allerede i dag ser vi et betydelig tidsspille som går med på å etterlyse svar fra andre helseforetak. Dette gir lengre svartider og forsinket behandling av pasienter. Medisinering og behandling med utgangspunkt i den enkeltes genetiske data, vil gi økende grad av behov for gjenbruk av rådata. En tilrettelagt IKT infrastruktur som skissert her vil medføre en vesentlig effektivitetsøkning. Dette vil kunne utfordre den gjeldende personvernlovgivningen som må gjennomgås i et slikt prosjekt for å finne en forsvarlig løsning som både ivareta personvernet og gir en rasjonell bruk av de genetiske data for behandling av den enkelte. Svartid på analyser er en svært viktig faktor for et effektivt helsevesen. Gjenbruk av lagrete data vil føre til vesentlig kortere svartider enn om analysen må utføres på nytt. En IKT infrastruktur som den vi her søker å etablere, er en nødvendig forutsetning for effektiv gjenbruk av genomdata. Etablering av en slik løsning, vil også måtte ta hensyn til gjeldende krav til personvern og forvaltning av ansvar som er tillagt den enkelte juridiske enhet. Databehandlingsansvarlig for den enkelte pasients genetiske data vil med dagens lovog regelverk være det helseforetak som har utført undersøkelsen. Dette bør imidlertid ikke være til hinder for at dataene kan lagres på samme fysiske sted. For den aktuelle infrastrukturen vil man ha behov for effektive rutiner som muliggjør at helseforetakene kan utlevere data til annet helsepersonell som har behov for disse i pasientbehandling.