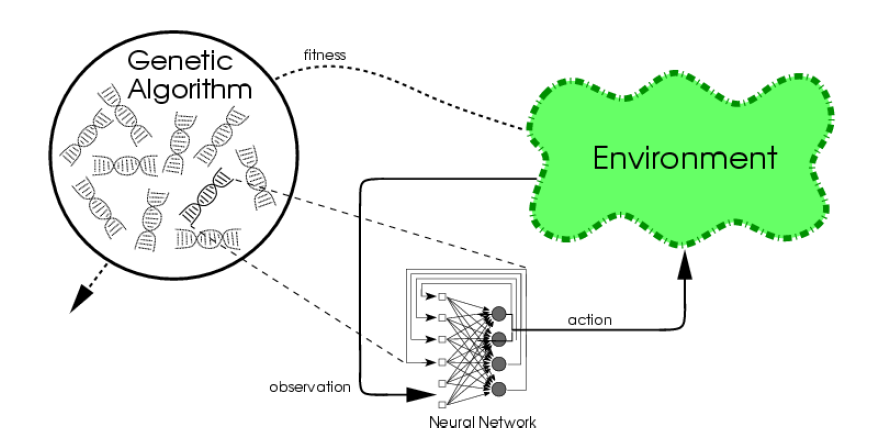
Despite rapid and impressive progress in deep learning over the last few years, many open challenges remain for AI-systems to reach the flexible problem solving abilities displayed by humans and animals. One way to address some of these challenges is by taking inspiration from evolution, which has produced the most impressive problem-solving systems we are familiar with: The brains of humans and animals. These projects will build on recent advances in population based search and training of neural networks, investigating how these may help overcome open challenges in Artificial Intelligence research. There are several different themes which could be relevant, and the specific project should be worked out with the student and supervisor(s) according to interests. Here are some example themes:
- A repertoire of brains. A recent trend in evolutionary algorithms is so-called Quality Diversity algorithms. Unlike traditional EAs, QD-algorithms do not aim to find a single near-optimal solution, but rather very many solutions that are interesting in different (pre-defined) ways. For instance, finding many different good ways that a robot could walk, where different styles could be resistant to different types of damage to the robot body. An intriguing idea is to use QD-algorithms to make many different "brains" where each brain solves a slightly different problem. For instance, each brain plays the same computer game, but with slightly different settings. Can such a "repertoire of brains" handle new challenges better than a single brain could? For instance, can it be used to adapt faster to new versions of a game? An intriguing variant here is to evolve a repertoire of robot bodies, for instance by evolving many different kinds of voxel-based robots.
- Weight agnostic neural networks. Weight agnostic neural networks (WANNs) are neural networks that can solve a problem even if their weights are randomized. In other words, it is the architecture of these neural networks that solve a problem, rather than their specific weights. Weight agnostic neural networks are a recent discovery, and many open issues remain, such as: What types of tasks can be solved by WANNs? Can WANNs generalize better to new tasks due to relying less on specific connections? Can WANNs learn to encode many different tasks at the same time?
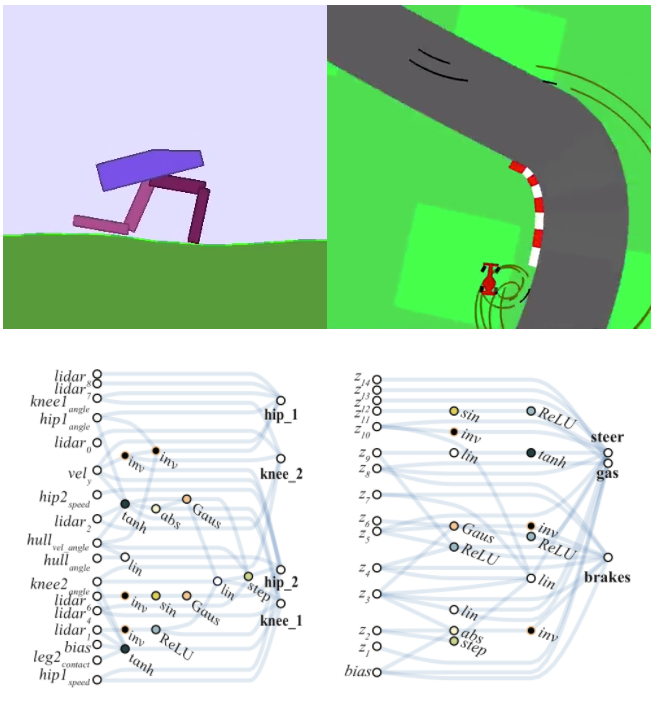
Weight-Agnostic networks that solve the tasks above independently of their weights. Picture from https://weightagnostic.github.io/ - Guiding neuroevolution with additional objectives. A powerful technique to improve the search for neural networks is to add extra objectives helping evolution towards promising areas of the search landscape. A common idea is to guide evolution by rewarding solutions that behave differently than others. An alternative idea, which we recently proposed and tested, is to guide evolution by rewarding solutions that are structurally different to others. An open question is which of these ideas works better for which kinds of problem. For instance, for problems with a very well defined structure, the latter may work better, while the former may work better for problems where there are deceptive traps.
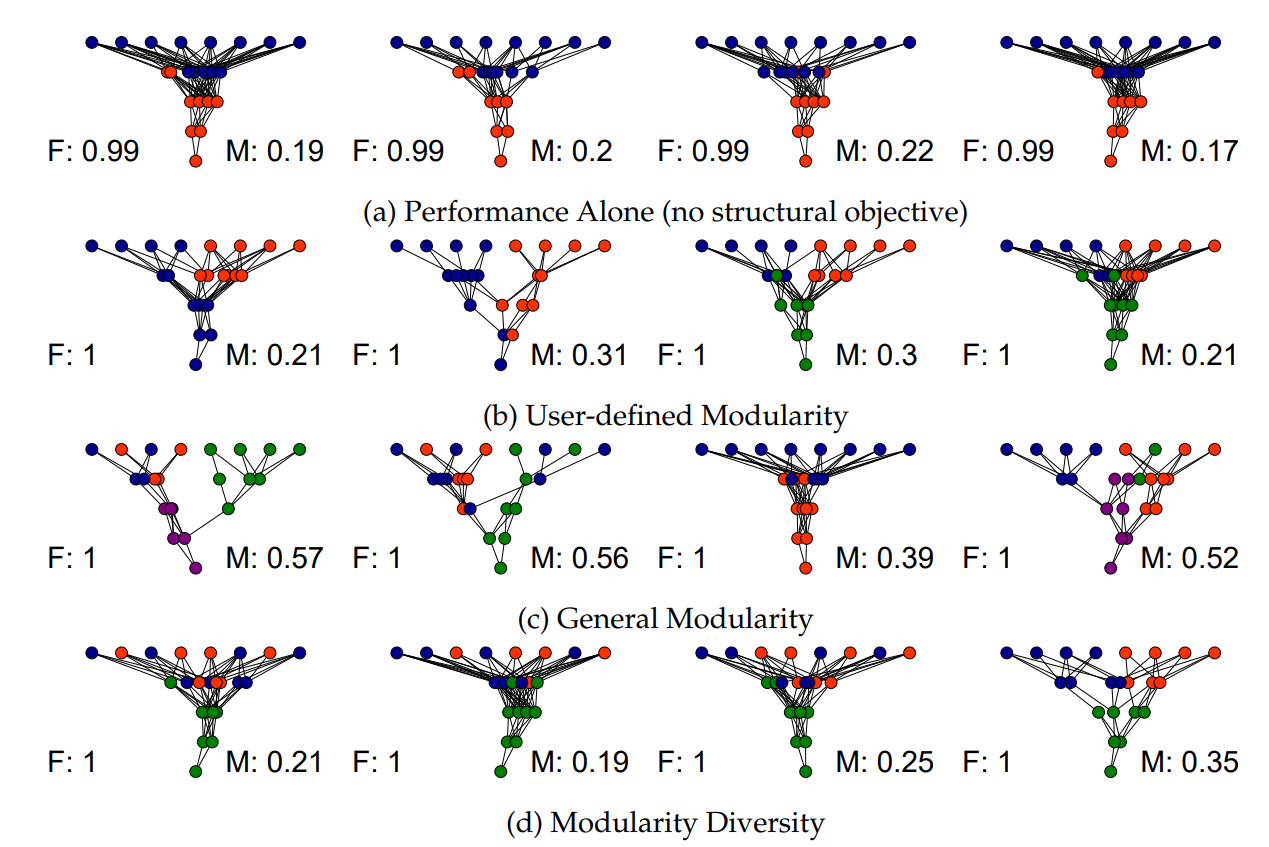
The effect on neural network structure of different guiding objectives. See details in https://arxiv.org/pdf/1902.04346.pdf - Open-ended evolution. Open-ended evolution builds on the idea of rather than searching for a single solution, searching for anything that is "interesting", potentially reaching complex solutions beyond what could be reached by objective-based search. A recent impressive demonstration of this is the POET algorithm, demonstrating that open-ended search can reach robot controllers that cannot be found by directly searching for them. With more and more Reinforcement Learning environments readily available online, there are now many exciting worlds to test open-ended evolution ideas within. One idea could be the Neural MMO world, where creatures compete in a simulated world for survival. But also other RL environments may be interesting to explore with open-ended search. This paper summarizes some of the most famous ones.

The neural MMO from neuralmmo.github.io Another important challenge in open-ended evolution is moving such techniques from the simple environments they are usually currently tested on and into more complex environments (or even the real world!). When we do this, we will have a "bootstrapping problem": If an environment is very complicated, the initial, often random, solutions will not get anywhere and search will therefore not get started. It could therefore be interesting to study whether it is possible to start open-ended search algorithms by starting them from known, well-functioning solutions, to kick-start the search. E.g. for the bipedal walker, to start it with some known walking gaits. Two important questions will be 1) Does such a kick-start limit the following creativity in the open-ended algorithm (e.g. causing it to get stuck in a certain type of solution)? and 2) Can this kick-starting reach well-performing solutions faster?
- Solving problems with sparse rewards. Typical reinforcement learning algorithms struggle when problems have sparse rewards, that is, when many actions have to be taken to reach a goal, but where those actions do not have an associated reward. A population of agents can help, if those agents are encouraged to explore different types of solutions/behaviors. Encouraging exploration, or curiosity, can help reach solutions even without any associated reward, by rewarding the discovery of anything that is new. A powerful recent algorithm building on such ideas is Go-Explore, which became the first to solve the difficult Atari game Montezuma's Revenge. While being a very promising first demonstration of Go-Explore, many open questions remain, such as: What kinds of problems can Go-Explore solve? Can it be adapted to real-world tasks? How does its exploration strategy compare to more traditional curiosity-based reinforcement learning algorithms?

The idea in Go-Explore, from here. - Combining Neuroevolution and Deep Learning. Backpropagation-based Deep Learning (DL) and Neuroevolution (NE) have different strengths and weaknesses. DL is good at extracting structure from large amounts of data, forming meaningful, compressed internal representations from high-dimensional inputs. For instance, a deep neural network can learn from many pictures what features are characteristic for a cup, or for a dog. However, as noted above, DL is typically not good at solving problems with sparse rewards. It is also not good at exploring many different strategies for solving a problem simultaneously. NE has the potential to overcome these limitations. A promising way to combine NE and DL is therefore to let the deep learning do the ``heavy lifting'', for instance learning to make predictions or recognize objects based on a large number of examples, and train a small action-selection component using NE with the pre-trained deep neural network as a back-end. A few different papers have explored this recently, and there is much room for exploring creative ways to combine these two techniques.
-
Reward tampering. Reward tampering is the problem that occurs when an algorithm finds a loophole in how we specify a reward or fitness function and solves a different problem than we intended. DeepMind recently demonstrated a new, simple setup for studying reward tampering, and demonstrated that Reinforcement Learning algorithms easily fall into the trap of tampering with a reward function rather than actually solving the problem. Can we explore and reduce this problem by using co-evolution of agents and environments? For instance, perhaps one could evolve environments and reward functions to have as little potential for tampering as possible, by simultaneously evolving agents that attempt to tamper with them - and rewarding those environments that agents are least successful with tampering with.
Reward Tampering as illustrated by DeepMind