
In 2021, the ROBIN group and RITMO centre start the new Research Council of Norway funded project – Predictive and Intuitive Robot Companion (PIRC, 2020–2025) – to contribute to making robot assistants work safely and effectively at the same time. We will apply our machine learning and robotics expertise, and collaborate with researchers in cognitive psychology, to apply recent models of human prediction to perception-action loops of future intelligent robot companions. The goal of the work will be to allow such robots to adapt and act more seamlessly with their environment than the current technology. We will equip the robots with these new skills and in addition, provide them with the knowledge that users they are interacting with, apply the same mechanisms. This will include mechanisms for adaptive response time from quick and intuitive to slower and well-reasoned. The models will be applied in two robotics applications with potential for very wide impact: physical rehabilitation and home care robot support for older people. You find a presentation of the project here. ROBIN has the assistant robot TIAGo from PAL Robotics that will be applied in the master projects below.
We would like to address the above mentioned challenges through these master projects:
Predictive and Alert Systems
Humans are superior to computers and robots when it comes to anticipating future events by applying multimodal sensing together with learned knowledge in choosing the best actions. Are we able to transfer these prediction skills into intelligent systems and also apply that knowledge in how the systems interact with human users?
That is what we would like to address in one or more mater projects; through collaboration with researchers in cognitive psychology who we collaborate with in the RITMO Centre of Excellence, we aim at applying recent understanding within the field to develop models to be applied in perception-action loops of future intelligent systems including smartphones and robots.
The project is concerned with introducing new technology by applying cognitive psychology concepts for shifting between instinctive reactions and slower well-reasoned response using prediction mechanisms. Human capabilities like prediction and instinctive reaction – even in a complex situation, are features that are important for humans as for future robots to be able to offer intelligent and effective human interaction. Developing such capabilities within robotics and smartphones is the overall goal of this project. This includes demonstrating how a system with the capability of being alert would increase user friendliness.
Cognitive control has been explored in cognitive psychology and neuroscience by referring to processes that allow information processing and behaviour to vary adaptively from moment to moment depending on current goals, rather than remaining rigid and inflexible. Cognitive control enables humans to flexibly switch between different thoughts and actions. Models with two modes of thought have been proposed in psychology; one being fast and instinctive and another being slower and with more reasoning involved (Kahneman, 2011). One may think that the latter is to be preferred but humans almost entirely use the instinctive one in their daily life. That is, we do not think much about what to do when we walk or cycle. The benefit is that we do tasks effectively and with little cognitive effort. However, if we fail in doing something, we have to slow down and try again with more reasoning until can manage it. Next time we may be able to do the same task in an intuitive way using that earlier learned knowledge (Li, 2016). Two earlier ROBIN master students have done projects on developing systems using the two modes, see [Norstein 2020] and [Tønnessen 2021].
References
[Kahneman 2011] D. Kahneman, “Thinking, Fast and Slow”, Penguin UK, 2011.
[Li 2016] T. H. S. Li et al., "Robots That Think Fast and Slow: An Example of Throwing the Ball Into the Basket," in IEEE Access, vol. 4, no. , pp. 5052-5064, 2016.
[Norstein 2020] Thinking fast and slow in intelligent systems, ROBIN Master thesis. https://www.duo.uio.no/handle/10852/79608
[Tønnessen 2021] Thinking Fast and Slow – PINE: Planning and Identifying Neural Network, ROBIN Master thesis https://www.duo.uio.no/handle/10852/90312
The tasks of the project:
- Get an overview of theory behind the two model system in humans and work undertaken on emulating it in artificial systems.
- Define an own experimental setup invoking a robot to work on developing a demonstrator of the thinking and fast and slow concept.
- Compare various implementations of the system.
- Write master thesis report
Model-based Reinforcement Learning for Tiago
Much of the progress in recent years has been from the area of model-free Reinforcement Learning, that is, the idea of trying to learn to solve a problem without forming an explicit internal model of the environment. Model-based RL attempts to solve two key challenges with model-free approaches: 1) They require enormous amounts of training data, and 2) there is no straightforward way to transfer a learned policy to a new task in the same environment. To do this, model-based RL takes the approach of first learning a predictive model of the environment, before using this model to make a plan that solves the problem. Despite these advantages of model-based algorithms, model-free RL has so far been most successful for complex environments. A key reason for this is that model-based RL is likely to produce very bad policies if the learned predictive model is imperfect, which it will be for most complex environments.
A way to alleviate this problem, making predictive models more feasible to learn, and thus more useful, is to keep the predictive model as small as possible, trying to learn only exactly what is necessary to solve a problem. For instance, if you are trying to model a car-driving scenario, it is not important to perfectly model the flight of birds you see in the distance or the exact colour of the sky. To drive safely and efficiently, we need to model a few key effects, such as the effect of our actions (speed/brake/turn) on the distance to pedestrians, on the speed of the car, and so on. This insight is the idea behind a recent technique called "Direct Future Prediction (DFP)", which solves RL problems by learning to predict how possible actions affect the most important metrics.

In this project, we aim to apply model-based Reinforcement Learning to training the assistive robot TIAGo. In doing so, it is important to explore how to best model TIAGo and his environment: If we model it in too much detail, learning will be too complex. Too little detail, and the learned environment model is of limited use. Finding an intermediate spot, such as the representation used in "Direct Future Prediction (DFP)" can help us keep learning efficient while still providing a useful environment model.
The tasks of the project:
- Read up on model-based RL, in particular methods applied to robots, and methods that try to balance the needs for a complete model with having a low model complexity.
- Identify a task that TIAGo can carry out where a model of his environment can be useful
- Set up an experiment, testing the benefit of TIAGo having a model of his environment when learning how to do his task, and perhaps also comparing models at different detail level/ complexity level.
- Write master thesis report.
Fast and Slow Reasoning with Model-Based Reinforcement Learning
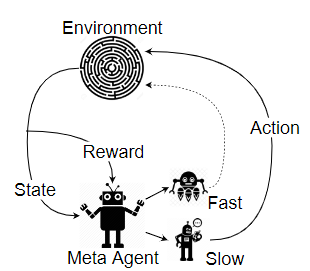
Model-based Reinforcement Learning aims to make AI agents learn more robust and transferrable knowledge by first learning to "understand" the world around them, and later using that understanding to learn how to act (whereas model-free RL agents learn how to act directly while interacting with an environment). This learned model also has the advantage that it can allow the agent to plan ahead, by "imagining" the outcome of its actions (Ha, 2018).
As described above, humans have been proposed to have two main forms of reasoning: One fast and instinctive, and another slower and with more reasoning involved (Kahneman, 2011). If balanced properly, these two forms of reasoning can allow fast response when needed, and more carefully planned responses when necessary (or when there is plenty of time).
This master's project proposes to combine the two concepts above: Can the ability to predict outcomes of actions from model-based RL and the ability to switch between slow and fast reasoning be combined? For instance, can we learn when to use (slow) predicted outcomes from the predictive model, and when to instead choose a (fast) "instinctive" action? The idea could take the following form:
- Train a predictive model of an environment, for instance using this approach.
- Train two RL models: One model-based that predicts future states and uses them for acting, and a model-free one that acts directly from current environment inputs.
- Train an agent to act optimally in the environment by using the two models above at the right moments: Can it learn to evaluate if a situation calls for immediate/instinctive responses, or if there is a need to think ahead to make the right decision?
- Learning here could for instance take as input the current state (e.g. an image of the situation the agent finds itself in) and produce as output the binary choice between the "fast" and the "slow" model. Can the agent via Reinforcement Learning learn to choose the right model at the right moment?
References
[Kahneman 2011] D. Kahneman, “Thinking, Fast and Slow”, Penguin UK, 2011.
[Ha 2018] Ha, David, and Jürgen Schmidhuber. "Recurrent world models facilitate policy evolution." Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018.
[Norstein 2020] Thinking fast and slow in intelligent systems, Master thesis. https://www.duo.uio.no/handle/10852/79608
The tasks of the project:
- Get an overview of theory behind the two model system in humans and work undertaken on emulating it in artificial systems.
- Define your own experimental setup including a problem to test the algorithm on and your own selection of model-free and model-based RL algorithms.
- Analyze the results: Did the agent learn to properly select between "fast" and "slow" thinking? Is there any regularity with regards to in which situations the agent chooses each form of reasoning?
- Write master thesis report
Planning ahead or Acting Instinctively
This idea is related to the one above on Fast and Slow Reasoning, and can be seen as a specific implementation/test of the ability to learn when to deliberate/plan ahead and when to act instinctively.
A recent paper extended the work on learning predictive models for reinforcement learning (Ha, 2018), with the ability to use such predictive models to plan ahead (Olesen, 2021). Planning in such a learned predictive model can be seen as similar to imagining future consequences of one's actions, and using such imagined scenarios to decide what to do. The picture below shows how the learned predictive model was used to imagine and plan trajectories for a simulated race car.

In the work of (Olesen, 2021), all actions are taken after imagining future outcomes and planning ahead - however, it is not studied if such imagined plans are actually always necessary. Perhaps, similarly to the theory of humans having different forms of reasoning (Kahneman 2011), these agents could also benefit from sometimes thinking "fast" (no planning, just acting instinctively) and sometimes slow (planning ahead, imagining outcomes of actions).
This transition from slow to fast thinking has been explored in reinforcement learning literature, and is referred to as planner amortization (Byravan, 2021). This idea was used in (Watanabe, 2023) to train a fast object-pushing skill for a robot manipulator from demonstrations provided by a slow sampling-based motion planner, as shown in the picture below. However, the question of which system to use under which situation was left unexplored.
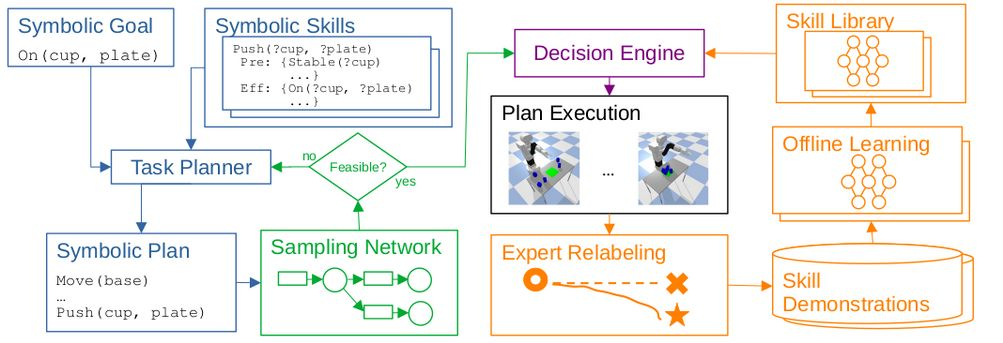
This question could be investigated by the following experiment:
-
Depending on the student's background studies and progress, it can be relevant to pursue slow thinking in a) a learned model (as in Olesen, 2021), b) a sampling-based approach (as in Watanabe, 2023) or c) both:
-
a) Train a predictive model of an environment, and implement a way to plan ahead by "imagining" consequences in this predictive model - for instance, following (Olesen, 2021).
-
b) Integrate a sampling-based motion planner into the task environment - for instance, following (Watanabe, 2023).
-
- Implement two different ways to select actions - one using planning, similarly to (Olesen 2021), and one using just the current state, e.g. following (Ha 2018).
- Train an agent to act optimally in the environment by using the two modes above at the right moments: Can it learn to evaluate if a situation calls for immediate/instinctive responses, or if there is a need to think ahead to make the right decision?
- Learning here could for instance take as input the current state (e.g. an image of the situation the agent finds itself in) and produce as output the binary choice between the "fast" and the "slow" model. Can the agent via Reinforcement Learning learn to choose the right model at the right moment?
References
[Kahneman 2011] D. Kahneman, “Thinking, Fast and Slow”, Penguin UK, 2011.
[Ha 2018] Ha, David, and Jürgen Schmidhuber. "Recurrent world models facilitate policy evolution." Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018.
[Olesen 2021] OLESEN, Thor VAN, et al. Evolutionary Planning in Latent Space. In: International Conference on the Applications of Evolutionary Computation (Part of EvoStar). Springer, Cham, 2021. p. 522-536.
[Byravan 2021] Byravan, Arunkumar et al. “Evaluating model-based planning and planner amortization for continuous control.” ArXiv abs/2110.03363 (2021): n. pag.
[Watanabe 2023] Watanabe, Shin et al. “Offline skill generalization via Task and Motion Planning.” ArXiv abs/2311.14328 (2023): n. pag.
The tasks of the project:
- Get an overview of theory behind the two model system in humans and work undertaken on emulating it in artificial systems.
- Define your own experimental setup including a problem to test the algorithm on and your own selection "slow" and "fast" action selection mechanisms.
- Analyze the results: Did the agent learn to properly select between "fast" and "slow" thinking? Is there any regularity with regards to in which situations the agent chooses each form of reasoning?
- Write master thesis report
Robot Sensing and Control for Physical Rehabilitation at Home
The objective of this project is to apply the developed models for prediction and adaptive response for a robot supporting in rehabilitation in a home environment. Thus, there has to be undertaken implementation and research within robot perception and control relevant for rehabilitation training tasks. In addition, user studies through human robot interaction experiments are to be performed. The project will be undertaken in collaboration with Sunnaas Rehabilitation Hospital.
References
A popular science introduction to physical therapy.
Fazekas, Gábor. (2013). Robotics in rehabilitation: Successes and expectations. International journal of rehabilitation research. 36. 10.1097/MRR.0b013e32836195d1.
Gassert, R., Dietz, V. Rehabilitation robots for the treatment of sensorimotor deficits: a neurophysiological perspective. J NeuroEngineering Rehabil 15, 46 (2018). https://doi.org/10.1186/s12984-018-0383-x https://doi.org/10.1186/s12984-018-0383-x
A master project undertaken i collaboration with Sunnaas: Haakon Drews: Classification of Error Types in Physiotherapy Exercises (2017)
The tasks of the project:
- Get an overview of theory behind predictive models and the two model system in humans and work undertaken on emulating it in artificial systems.
- Define an own experimental setup to work on developing a robot demonstrator of the psychology concepts. Relevance to rehabilitation should be taken into account.
- Compare various implementations of the system.
- Write master thesis report
Home Care Robot Support
The objective of this master project is to apply the developed models for prediction and adaptive response for a robot contributing to home care. The research will be focused on two different tasks: preparing food in the kitchen and/or interacting with a human with regards to bringing food etc and returning remains. Thus, there has to be undertaken implementation and research within robot perception and control, as well as user studies, relevant for the home care tasks.
Reinforcement learning will be relevant, including learning a library of standard robot tasks. That is, a library of basic behaviours are trained (e.g. “move arm 10 cm to the left”), and then higher-level behaviours (e.g. “pick up object”) are learned as combinations of more basic behaviours. Specifying each behaviour in such a library manually is time consuming and risks not identifying all relevant sub-behaviours. Automatic methods for building hierarchies of behaviours therefore exist (see Cully & Demiris below). However, these have so far mainly been tested on simpler robot interaction scenario. A valuable contribution of this work would therefore be to suggest and test how to extend such techniques to learning complex and useful behaviours for home care robots.
References
Robinson, Hayley & Macdonald, Bruce & Broadbent, Elizabeth. (2014). The Role of Healthcare Robots for Older People at Home: A Review. International Journal of Social Robotics. 6. 575-591. 10.1007/s12369-014-0242-2.
Van Aerschot, L., Parviainen, J. Robots responding to care needs? A multitasking care robot pursued for 25 years, available products offer simple entertainment and instrumental assistance. Ethics Inf Technol 22, 247–256 (2020). https://doi.org/10.1007/s10676-020-09536-0
A. Cully and Y. Demiris, “Hierarchical behavioral repertoires with unsupervised descriptors,” in Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, Jul. 2018, pp. 69–76, doi: 10.1145/3205455.3205571.
The tasks of the project:
- Get an overview of theory behind the two psychology models and state-of-art within service robots applied in human-robot interaction scenarios.
- Get an overview of techniques for learning hierarchies of robot skills, enabling the robot to learn complex tasks as sequences of simpler ones.
- Define an own experimental setup to work on developing a demonstrator incorporating the psychology concepts where the robot is able to learn selected human supportive tasks, as well as demonstrating the learning of complex tasks as a combination of simpler ones.
- Compare various implementations of the system.
- Write master thesis report
The RITMO - Centre for Interdisciplinary Studies of Rhythm, Time and Motion started in 2018. Researchers in the network come from the ROBIN group (Informatics), FRONT Neurolab (Psychology), and the Department of Musicology, and have access to state-of-the-art laboratories.