
We never like excessive repetitions in natural languages. For instance, in English, we would state the full name of a person for the first occurrence in a document, but for subsequent mentions we typically switch to she/he, him/her, or other expressions.
Coreference resolution is the task of identifying all expressions referring to the same entity in a text. It is an important step for solving other NLP problems, such as question answering (QA), information extraction (IE), machine translation (MT), and document summarization.
Consider the following example:
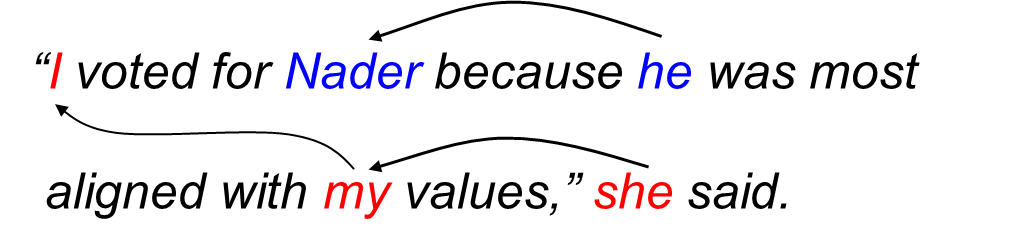
"I", "my", and "she" belong to the same cluster (or coreference chain), and "Nader" and "he" belong to the same cluster.
Coreference resolution is challenging, because natural language is often ambiguous and requires knowledge of the world to understand. In this project, you will approach the task with state-of-the-art neural models. In an ongoing collaboration between LTG and the National Library, the texts that comprise the Norwegian Dependency Treebank are currently being annotated with information about coreference. In this project we seek to work on coreference resolution for Norwegian and/or English or other languages, possibility also exploring the use of cross-lingual methods and transfer learning.