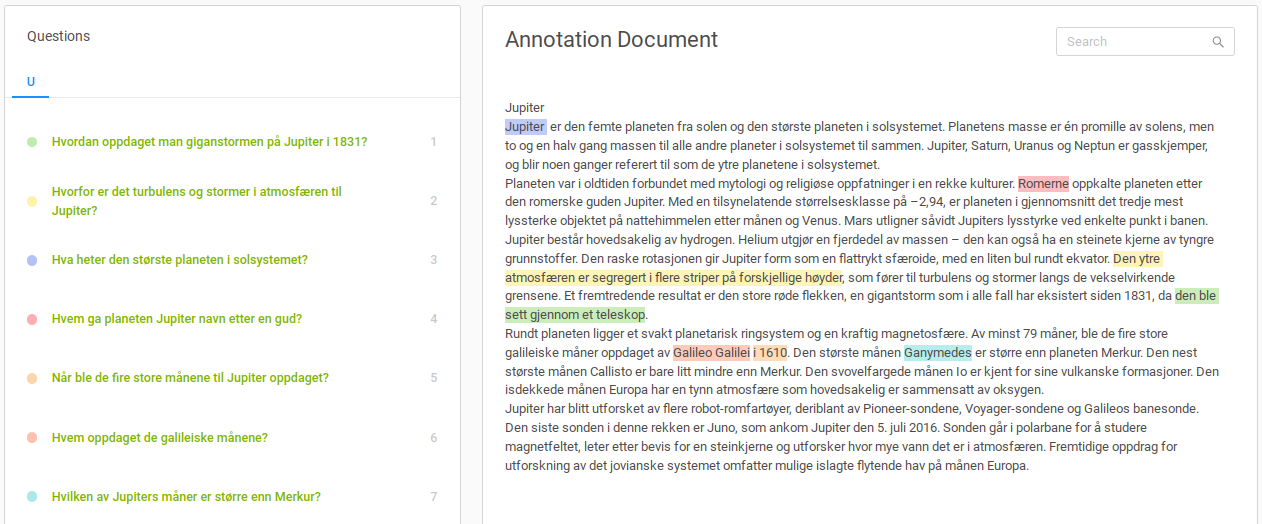
The first Norwegian QA dataset NorQuAD was recently released. The dataset was the result of a small-scale data annotation effort led by LTG. While the modeling results based on this dataset were promising there remains many possible areas of research to improve QA benchmarking for Norwegian.
This thesis can take several directions, depending on the interests of the student (and may also be conducted by a team of two students). Some possible directions include:
- assessing the effect of data augmentation approaches to enlarge the NorQuAD benchmark
- adapting the NorQuAD benchmark for instruction-tuning of generative LLMs
- developing a neural, generative QA model for Norwegian
- and others
Read more:
Ivanova, Sardana; Andreassen, Fredrik Aas; Jentoft, Matias; Wold, Sondre & Øvrelid, Lilja (2023). NorQuAD: Norwegian Question Answering Dataset. In Alumäe, Tanel & Fishel, Mark (Ed.), Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa).