Fra data innsamlet i eksperimenter eller observasjonsstudier velges en stokastisk eller deterministisk modell. I den stokastiske modellen er det en sannsynlighetsfordeling som beskriver variasjonen. Deretter følger hypotesetesting, estimering av parametre i modellen med tilhørende konfidensintervall, test av hypoteser og modellseleksjon. Modellen tilpasses data. Forhåpentligvis har man funnet svar på spørsmålet man stilte. Imidlertid er dette en iterasjonsprosess og man går tilbake til spørsmålet, og stiller nye spørsmål. Dessuten bør man formulere hva er den praktiske betydningen av forsøket i hvilken grad gir det økt forståelse av biologiske eller økologiske prosesser ? Hva er betydningen for mennesker, dyr eller planter ?
Metadata er informasjon som beskriver data, navn på variable, måleenheter, når, hvor og hvordan er data samlet. Kolonnenavn (variabelnavn) er første rad i datasettet.

Det har blitt stilt mange kritiske spørsmål om metoder brukt i hypotesetesting. Velger allikevel og gi en oppsummering av denne metoden: Det skal være to tydelige hypoteser, nullhypotese og alternativ hypotese. Nullhypotesen (H0) defineres som ingen forskjell mellom kontrollgruppe og behandlet gruppe. Alternativ hypotese (HA) formuleres som en forskjell mellom eksperimentelle grupper.
Den eksperimentelle enhet kan være et individ eller en gruppe individer. Du må kunne bestemme konfidensintervall for den eksperimentelle enhet. Hvor mange individer trenger du, og hvordan skal du foreta prøveuttak for å få et representativt og randomisert utvalg av prøvepopulasjonen ? Stikkord er randomisering og prøveutvalg, randomisering av individer som skal brukes som eksperimentelle enheter. Hver individ kan gir et nummer fra 0-n, med utvelgelse skjer med bruk av slumptall, nummer fra hatt, myntkast,osv. Individer kan velges ut fra et areal via slumptall for geografiske koordinater. Antall, utvelgelse og størrelse på prøveflater og linjetransekter er andre parametre som må følge god design. Individer og behandlinger velges og gis tilfeldig.
Hvordan skal du ta ut representative prøver fra prøvepopulasjonen? Hvor mange replikater, A-G ?
Hva er naturlig variasjon og karakteristiske egenskaper til prøven? Hvilken teststyrke skal du bruke ? I mange tilfeller finnes det allerede tilgjengelige data i sekvensdatabanker eller e.g. fra Statistisk sentralbyrå (SSB).
Hvilke variable inngår i studiet ? Hvilken type studiedesign vil du velge ? Hvilke variable inngår, hvordan skal de måles/estimeres ? Finnes det uavhengige variable som det er lett å glemme dvs. konfundering ? En kontroll vil vanligvis bety ingen behandling, men det er mange typer kontroller og det kan sjelden bli for mange av dem.
Negative kontroller forventes ikke å gi noen forandring under forsøket.
Positive kontroller brukes for å se at forsøkssystemet responderer som forventet.
Hvis man bruker et kjemisk stoff, må det være en egen kontroll for middelet som stoffet er løst i (formidlerkontroll). En indre standard vil si å tilsette en kjent mengde stoff som man kan følge samtidig med stoffet man undersøker. Den indre standarden må ha kjemisk egenskaper som er svært lik det stoffet man undersøker, men må ikke påvirke prosess eller målesystem. En simulert kontroll, placebo (falsk behandling), og imitert kontroll er andre eksempler. Hvis flere personer skal utføre samme type måling eller observasjon må personellet trenes og standardiseres. I dobbel blindtest forsøk vet verken subjekt (forsøksperson) eller eksperimentator hvilken behandling som gis. Alt måleutstyr må kalibreres i henhold til gjeldende internasjonale standarder. Bruk av kjente datasett brukes til å kontrollere at programpakker gjør utregninger som de skal.
Stratifisert tilfeldig prøveuttak vil si at undergruppene har en spesiell egenskap og deretter velges det tilfeldig fra undergruppene. For eksempel at man deler subjektene først etter kjønn, og deretter velges individer tilfeldig fra hvert av kjønnene. Deretter deles de utvalgte individene fra hvert kjønn i tilfeldige grupper som gis forskjellige behandlinger.
I matched par prøveuttak velges det ut par av objekter med samme kjønn, høyde, vekt, alder, rase (dyr), genetikk, og i hvert par velges tilfeldig hvem av individene i paret som får bhendling. Et annet design er at samme individ gis forskjellige behandlinger over tid, gitt i forskjellig rekkefølge.
Spørreundersøkelser er ofte beheftet med dårlig design og prøveuttak. Avkryssing i en av to bokser, Ja eller Nei, om man er enig eller uenig i en påstand har bias (skjevhet), et systematisk avvik, fordi den som svarer gjør det frivillig, og det er ikke tilfeldig hvilke individer som bruker internet. Spør man ”mannen i gata” er det bias hvem som er tilstede. Underdekning vil si at deler av populasjonen er utelatt. I kliniske undersøkelser kan det skje at kvinner ikke blir representativt utvalgt pga. fødsler, menstruasjon etc. Spørsmål av typen: ”Er du enig i…. ” gir et spesielt svar. Spør man: ”Er du positiv til atomkraft ?” så gir dette et helt annet svarbilde enn om du spør: ”Vil du ha at lager for langtlevende (>100000 år) høyradioaktivt avfall fra atomkraft i din kommune eller nabolag ?” Hvis du spør dem som befinner seg innenfor bomringen i Oslo om de er fornøyd med bomringen, så får du et annet svarbilde enn om du spør dem som befinner seg utenfor. I spørreundersøkelser kan individer ha personlige motiver for å skjule ting eller påberope seg meninger eller handlinger som de ikke har.
I mange tilfeller er et stort prøveantall ikke alltid mulig, for eksempel ved merking-gjenfangstforsøk.
Et pilotstudium med et lite antall organismer kan brukes for å teste prosedyrer og metoder.
Statistisk signifikans vil si en observert effekt så stor at den sjelden vil skje ved en tilfeldighet. I ethvert studiedesign skal det være etiske betraktninger om etikk, risiko, konfidensialitet, anonymitet. Hva med atferdseksperimenter med mennesker hvor formålet egentlig er skjult for dem som deltar.
Hvis vi har en normalfordelt populasjon N(μ,σ) så vil ifølge sentralgrenseteoremet fordelingen av gjennomsnittsverdier (middeltall) også bli normalfordelt N(μ,σ/√n). Standardavviket til gjennomsnittsverdiene kalles standardfeil (SE) og er lik σ/√n. 95% av gjennomsnittsverdiene (p=0.05) vil bli liggende innenfor konfidensintervallet (CI):
\(\text{95% CI}= \mu\; \pm\; t \cdot SE= \mu\; \pm\; 1.96 \cdot SE= \mu\; \pm\; 1.96 \cdot \frac{\sigma}{\sqrt{n}}\)
hvor t er fra t-fordelingen for n-1 frihetsgrader.
William S. Gosset ved Guinness bryggeriet introduserte t-fordelingen (Students t-fordeling) i 1908, en fordeling som tar hensyn til forsøk med et lite antall prøveverdier.
t-fordelingen har form som en normalfordeling, men med mer sannsynlighet i halene. I en en-prøve t-test undersøkes det om gjennomsnittet av våre verdi er signifikant forskjellig en kjent hypotetisk verdi. De kritiske verdiene for t (t-observator) er gitt ved hvor µ er gjennomsnittsverdi:
er gjennomsnittsverdi:
\(t=\displaystyle\frac{\overline X - \mu}{\frac{s}{\sqrt{n}}}\)
som har en t-fordeling med n-1 frihetsgrader.
Students t-test brukes til å undersøke om det er forskjell mellom to uavhengige grupper gjennomsnitt fra to behandlinger, selv om det er forskjellig antall replikater i de to prøvene. Prøvene må representere et tilfeldig (randomisert) utvalg fra populasjonen, og må være normalfordelte. I en toprøve-t-test sammenlignes gjennomsnittet av to statistisk uavhengige grupper X1 og X2. Nullhypotesen er at de to gjennomsnittene er like.Vi har to datasett X1 og X2 med henholdsvis antall replikater n1 og n2. Beregner første gjennomsnittet av X1 og X2, og deretter variansene s12 og s22, og t. Sammenligner med den kritiske tabellverdien for t. Det er flere typer t-tester: Ofte er det behov for å avgjøre om to middeltall er like eller ikke, det vil si om to populasjoner (μ1,σ1)og (μ2,σ2) er forskjellig. En to-prøve t-observator med estimat av variansen s2:
\(t=\displaystyle\frac{\overline X_1- \overline X_2}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}\)
Vi ser at det er de to standardfeilene som står under brøkstreken. Antall frihetsgrader (n1-1, n2-1)
Parvis-t-test brukes på parvise data og undersøker om differansen (d) i dataparene er signifikant forskjellig. For eksempel måling av de samme individene før og etter behandling.
\(\displaystyle t= \frac{d}{\frac{s_ d}{\sqrt{n}}}\)
Homogen og lik varians er en forutsetning for t-test og variansanalyse (ANOVA). Det brukes en F-test som sammenligner forholdet mellom varians i de to gruppene og sannsynligheten beregnes ut fra den kritiske tabellverdien for F-fordelingen.
Når man skal sammenligne to prøver er det flere muligheter. Man kan sammenligne de to variansene med Fisher´s F-test, eller sammenligne de to gjennomsnittene med normalfordelte feil med Students t-test. Hvis feilene er ikke-normalfordelte kan man bruke en ikke-parametrisk rang test, Wilcoxon´s rang test. Hvis det er to forhold man skal sammenligne bruker man en binomial test. Skal man undersøke om de to prøvene er korrelerte gjøres dette med en korrelasjonstest, enten Pearson´s-korrelasjon eller Spearman´rang korrelasjonstest.
t-tester er en gruppe tester (en-prøve t-test, toprøve-t-test og parvis t-test) basert på t-fordelingen. Normalfordelte data er en forutsetning for å kunne bruke en t-test og dette må undersøkes i et kvantil-kvantilplot (QQ-plot).
Her er et eksempel som viser hvordan QQ-plot kan se ut avhengig av statistisk fordeling:
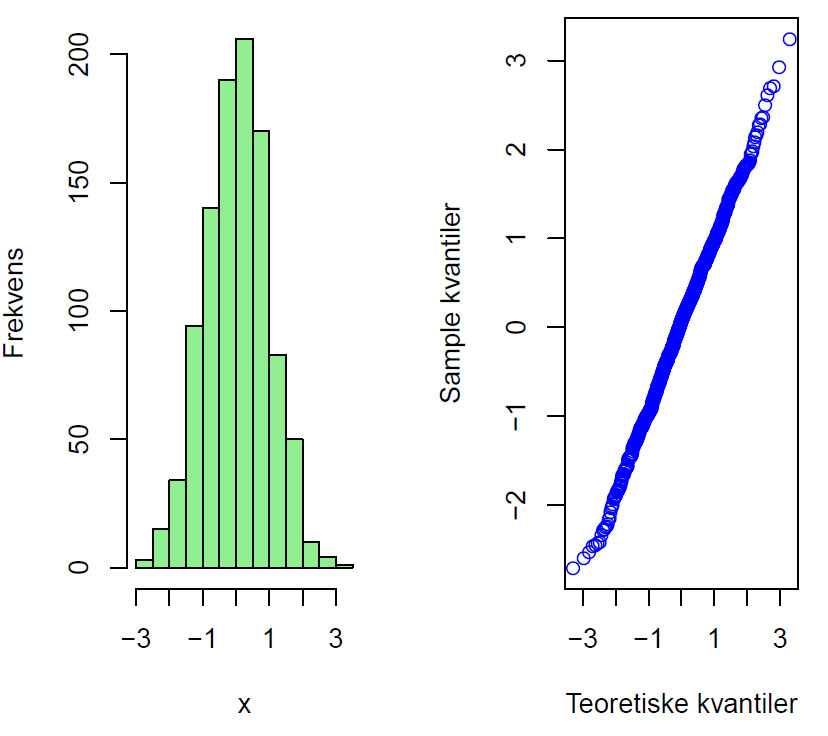
For normalfordelte data gir kvantil-kvantilplot en rett linje.
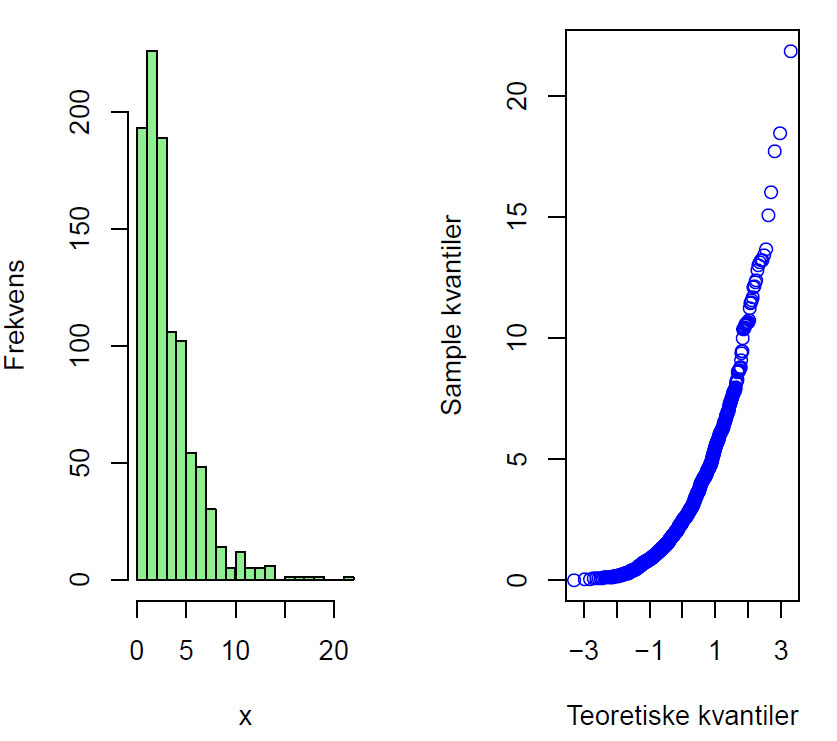
QQ-plot for skjevfordelte data.
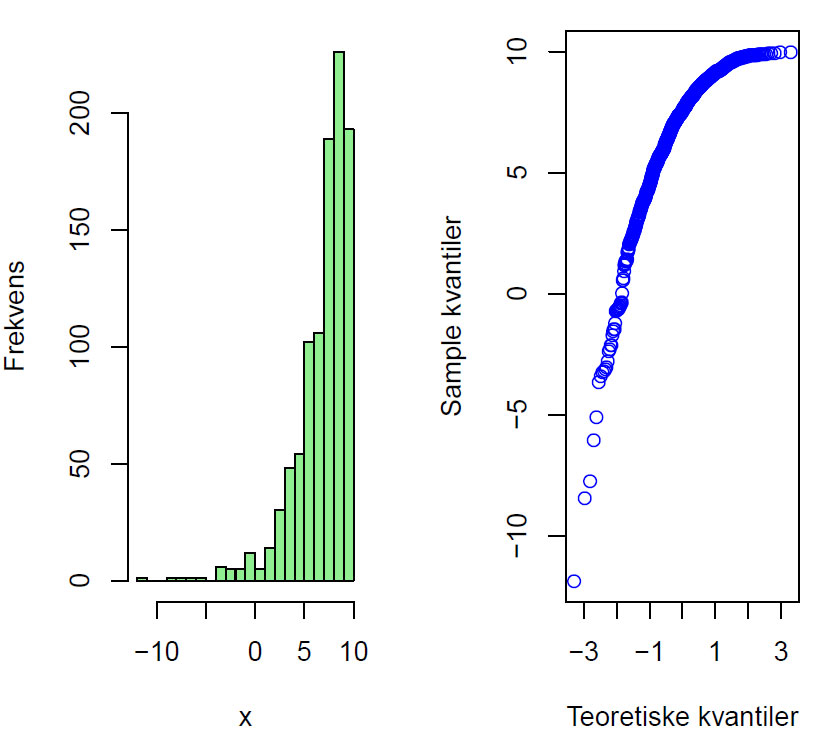
QQ-plot for skjevfordelte data.
Wilcoxon rangsumtest
Ikke-parametriske tester bygger på få forusetninger når det gjelder sannsynlighetstetthet, og brukes ofte på små prøver som ikke følger normalfordeling. Wilcoxon test er en ikke-parametrisk test som tilsvarer t-test. I stedet for å bruke gjennomsnittsverdien rangeres data fra den minste til den største og man beregner median-verdien.En-prøve Wilcoxon-test kalles ofte Wilcoxon Signed rank hvor medianverdien i et forsøk sammenlignes med den kjente empiriske medianverdien. Wilcoxon har på samme vis som t-testen utgaver for parvis og toprøve.