- Mer utførlig om statistikk (pdf 541kb)
- Litt regning og matematikk (pdf 300 kb)
- Den vitenskapelige metode
- Forsøket
- Deskriptiv statistikk
- Randomisering (tilfeldig utvalg) og replikat (gjentak)
- Tilnærmingsverdi og gjeldende siffer
- Normalfordeling
- Konfidensintervall
- Sammenligning av middeltall fra to eller flere grupper
- Z-score - standard normalt avvik
- Students t-test
- Chi-kvadrat test
- Korrelasjon
- Regresjon
- Lineær regresjon (minste kvadraters metode)
- Binomial fordeling
- Poisson fordeling
- Variansanalyse
- Litteratur
Statistikkprogrammet R
Det finnes en lang rekke statistikkprogrammer som kan brukes til analyse av et datasett. Det ligger muligheter i Excel, og i tillegg finnes avanserte programmer bl.a. SPSS, SPLUS, SAS, og Minitab. Imidlertid kan statistikkprogrammet R anbefales meget sterkt for bruk i videregående skole, høyskoler og universiteteter. Her er en liten bruksanvisning som viser muligheter som ligger i programmet: Bruksanvisning for R
I noen sammenhenger kan det være aktuelt å bruke matematikkprogrammet Matlab: Bruksanvisning for matlab (uferdig), og skal man løse Lotka-Volterra-ligningen bør man vite litt om differensialligninger. Litt mer om differensialligninger.
Den vitenskapelige metode
Vitenskap er en fagdisiplin brukt til å undersøke og forstå våre omgivelser. Grunnlaget for all vitenskap er å kunne observere. Vitenskapen gjør fremskritt ved å fremsette og teste hypoteser. Hypoteser er mulige forklaringer på observerte fenomener. Formålet med vitenskapelige eksperimenter er å se om hypotesene stemmer med virkeligheten. Vi kan teste om en hypotese er sann eller falsk. En hypotese kan beholdes eller forkastes, men den kan aldri bevises. Vi trenger statistikk for å kunne beregne om et avvik fra hypotesen er signifikant. Sannheter er observasjoner som alle er enige om at er sanne. Induktiv logikk er generaliseringer ut fra en enkelt observasjon. Deduktiv logikk er av typen "hvis.... så", at man fra en generell hypotese kan forutsi hva som vil skje. Et eksperiment må alltid ha en kontroll som det kan sammenlignes med.Forsøket
To frø som spirer og gis lik behandling, med samme type gjødsel, vanning, lys og temperatur blir nødvendigvis ikke like store. Dessuten er alle målinger beheftet med feil som er forskjellen mellom målt verdi og sann verdi. Slike feil er systematiske og konstante målefeil og tilfeldige målefeil som skyldes manglende kontroll med ytre faktorer. Måleresultater hvor det brukes biologisk materiale varierer mer enn rene fysiske målinger uten biologi. Et forsøk må planlegges før det kan utføres følgende må bestemmes:- 1. Hva er formålet ?
- 2. Hvilken metode skal brukes ?
- 3. Hvor følsomme og nøyaktige målingene må være ?
- 4. Kostnadene i tid og penger ved hver av målingene.
- 5. Hvilke variable finnes og hvordan de kan kontrolleres ?
- 6. Hvordan man skal ta ut prøver og hvor mange prøver man trenger.
Deskriptiv statistikk
Deskriptiv statistikk er systematisk organsiering og presentasjon av tallmateriale. Omfatter middeltallet, standardavvik, standardfeilen til middeltallet, konfidensintervallet til middeltallet, skjevhet, kurtosis, median, maksimums- og minimumsverdi og intervall. Det arimetiske middeltallet /middelverdien for en serie målinger xi , antall n,(observasjoner) beregnes ved å dividere summen av observasjoner med antall observasjoner.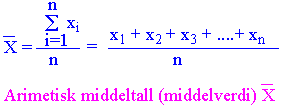
my, snittet av populasjonen, som finnes ved å foreta et uendelig antall målinger finner vi aldri. Vi bruker greske bokstaver for å beskrive populasjonen, de sanne verdiene som vi aldri finner, men som vi lager et estimat for. Flere individuelle målinger samles seg omkring et middeltall. Når vi angir et måleresultat skal vi angi et mål på variasjonen av resultatet. Jo flere forsøk og måledata vi skaffer oss i et eksperiment desto nærmere kommer vi de sanne tallene. Graden av spredning av målingene rundt middeltallet kalles variansen (s2). Variansen er summen av kvadratene av avvikene fra middeltallet for hver verdiVariansen av populasjonen ers2 Variansen av en prøve tatt fra populasjonen er gitt som. I de fleste tilfeller kjenner vi ikke s og må bruke s til å gi et estimat av s (sigma).
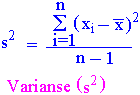
n er antall målinger og vi bruker n - 1 siden en av målingene har blitt brukt til å beregne middeltallet . Man tar kvadratet til differensen mellom hver enkelt observasjon og det arimetiske middeltall, kvadratene summeres og divideres på n-1. Summen av kvadrerte avvik kalles kvadratsummen (sum of squares (SS)).
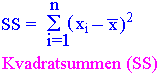
Kvadratsummen dividert på antall frihetsgrader kalles middelkvadratet (Mean square (MS)). Standardavviket (s) som er det vanligst brukte mål på variasjon; er kvadratroten av variansen.
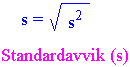
En annen form for gjennomsnitt er median. Det er den verdi hvor halvparten av målingene ligger under og den andre halvparten over. Median er den variabelen som deler den totale frekvensen i to halvdeler. Mode (modalverdi) er det tallet som forekommer oftest. Fordelingen kan ha bare en topp (unimodal) eller to topper (bimodal). For tallene 26, 8, 6, 5, 4, 3, 2, 2 vil middeltallet være 7, median vil ligge mellom 4 og 5 og mode er 2. For en perfekt symmetrisk fordeling vil median, mode og middeltall være like. Er det en skjev fordeling blir de forskjellige. Median for følgende tall 9.2, 11.5, 13.2, 19.7, 29.4 og 50.1 vil være 16.45. En samling middeltall vil også ha en fordeling og standardavviket til denne fordelingen kalles standardfeilen. Standardfeilen (S.E.) er standardavviket til middeltallene er gitt som:
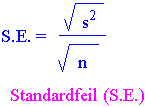
s er standardavviket til prøve. Ser vi på fordelingen av middeltall blir også disse normalfordelte på samme vis som enkeltobservasjonene blir normalfordelte. Dette forklares ut fra Sentralgrense-teoremet. Det sier at for prøves med tilstrekkelig størrelse så vil den virkelige fordelingen av middeltallene fra disse prøvene bli normalfordelte. Fordelingen av middeltall vil nærme seg mer og mer normalfordelingen når prøve størrelsen øker. Men hva med middeltallet for middeltallene ? Jo det blir populasjonsmiddelet, den sanne Det er av begrenset verdi å sammenligne variasjon i data hvor middeltallet er svært forskjellig. Man bruker da variasjonskoeffisienten (VC) som uttrykker variasjon i forhold til middeltallet i %. F.eks. hvis middeltallet er 3 og S.D. 0.54 er VC=0.54/3·100 % = 18 %. m. Hva er da standardavviket til fordelingen av middeltall ? Det blir ikke standardavviket til populasjonen, men vi deler standardavviket på kvadratroten til prøve-størrelsen og får da standardfeilen. For å beregne standardavviket til fordelingen av middeltall må vi vite standardavviket til populasjonen og antall tilfeller/observasjoner i hver prøve. Standardavviket til en fordeling av middeltall kalles altså standardfeilen til middeltallet (angitt som ovenfor).
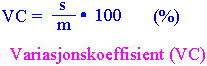
Randomisering (tilfeldig utvalg) og replikat (gjentak)
Det er to krav for et godt eksperiment og det er randomisering (tilfeldig utvalg) og gjentak (replikat). Replikat vil si at behandlingen gis til mer enn en eksperimentell enhet. Det er ikke noe fast svar for hvor mange eksperimentelle enheter man trenger per behandling. Før vi svarer må vi vite noe om presisjonen vi krever. Venter vi å finne signifikante forskjeller på 2 %, 20 % eller 50 % ? Hvor stor er variasjonen innen hver eksperimentell enhet ?Tilnærmingsverdier og gjeldende siffer
Hvis vi måler lengden til en plante og finner at den er 10.7 cm, mener vi at verdien må ligge mellom 10.65 og 10.75 cm. Skriver vi 10.70 cm må verdien ligge mellom 10.695 og 10.705. 10.7 og 10.70 er altså to forskjellige måleresultater, og kalles tilnærmingsresultater. Når vi måler at planten er 10.7 cm er usikkerheten 0.05 cm som er lik den maksimale avrundingsfeil. Hvor presise skal vi være med en måling ? Som en tommelfingerregel skal det være mellom 30 og 300 enheter mellom største og minste observasjon. Hvis vi måler lengder på blader og finner at det lengste er 67 mm og det korteste 59 mm tilsvarer dette 67-59= 8 enheter, noe som er for lite. Måles lengden til 67.4 mm og 58.8 mm blir dette 674-588= 86 enheter som derved er nøyaktig nok. Tallet 10.7 har 3 gjeldende siffer. Det samme har 4.00 og 0.00457. Nuller foran tallet teller ikke som gjeldende siffer. Skal vi skrive 8000 med 3 gjeldende siffer skriver vi 8.00 103. Hvis vi adderer eller subtraherer skal svaret angis med så mange desimaler som det leddet som har færrest desimaler: 3.5 cm + 7.88 cm + 10 cm = 21 cm Hvis vi vi multipliserer eller dividerer skal svaret angis med samme antall gjeldende siffer som det tallet som har færrest gjeldende siffer og inngår i beregningen. 3.5 cm x 7.88 cm x 10 cm = 0.28 103 cm3. Ved målingene kan det oppstå systematiske feil f.eks. hvis vekten viser feil. Slik feil virker ensidig og det kan korrigeres for slike hvis man oppdager dem. Tilfeldige feil er årsaken til at man ikke får samme resultat hver gang man måler samme prøven. Er det en tidsavhengig måling kan det skyldes at man ikke bruker samme tid ved hver måling.Fordelinger
Det finnes forskjellige sannynlighetsfordelinger av kontinuerlige og diskontinuerlige variable. For kontinuerlige variable har vi normalfordeling, t-fordeling, F-fordeling og chikvadratfordeling. To hovedtyper fordelinger er knyttet til diskrete variable: binomial fordeling og Poisson fordeling.Normalfordeling
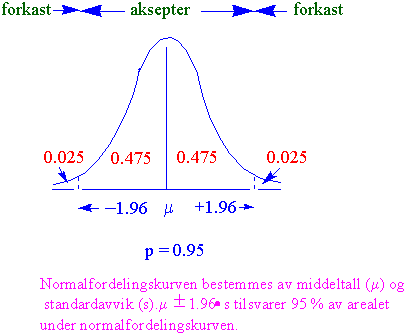
Når måleresultatene samles rundt middelverdien og målingene mindre og større enn denne verdien forekommer omtrent like ofte med en assymptotisk tilnærming mot abscissen jo lenger vi kommer vekk fra middeltallet, har vi sannsynligvis en normalfordeling. Hvis antall målinger fordeles i klasser få man en frekvensfordeling av resultatene og frekvensfordelingen vil nærme seg normalfordeling. En matematisk ligning definerer normalfordelingen. For et middeltall og et standardavvik bestemmer denne ligningen hvilken prosentdel av observasjonene som faller hvor i forhold til middeltallet. I en normalfordeling har middeltallet, median og mode alle samme verdi. En normalfordeling kan ha hvilket som helst middeltall og standardaviik, men prosentene av tilfellene som faller innenfor et spesielt antall standardavik fra middelet blir alltid det samme. Det er en kontinuerlig fordelingen for frekvensen av x = f(x). Når f(x) plottes mot x fås normalfordelingskurven også kalt Gauss-kurven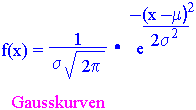
blir 95 %. 1.96 blir en konfidensgrense.
![]()
Konfidensintervall
Innenfor hvilket intervall er resultatet sant ? Konfidensintervallet kan beregnes fra Student´s t- test.Vi kan beregne de øvre og nedre grenser, et intervall, som inneholder populasjonsmiddelet i 95 % av tilfellene, et konfidensintervall. Vi vet som tidligere nevnt aldri populasjonsmiddelet, men vi kan beregne et intervall rundt vår prøve middeltal som inneholder det sanne populasjonsmiddelet i 95 % av tilfellene. Konfidensintervallet for middelet av en stor prøve (> 30) er gitt ved at det er 95 % sannsynlig at populasjonen faller innenfor middeltallet ± 1.96·S.E. Det er 99 % sannsynlig at populasjonen faller innenfor middeltallet ±2.58·S.E. Hvis vi derimot har en liten prøve må det legges inn en korreksjonsfaktor: 95 % konfidensintervall= middeltallet ± t·S.E. Når prøvestørrelsen er stor blir standardfeilen liten. I en nomalfordeling vil 95 % av verdiene ligge innenfor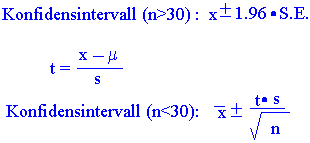
Sammenligning av middeltall fra to eller flere grupper
Signifikans-tester
Statistiske metoder som biologene bruker er av to typer: parametriske som forutsetter normalfordeling og ikke-parametriske. Ikke-parametriske tester gjør om observasjonene til rangeringer.. Signifikanstester brukes når vi skal teste hypotesen om at to uavhengige middeltall er forskjellige. Sentralgrense-teoremet gjelder ikke bare middeltall, men også forskjellen mellom middeltall. Når er forskjellen mellom to middeltall stor nok til at du antar at de to prøvene er fra populasjoner med forskjellig middeltall ? Svaret avhenger av hvor villig du er til å ta feil. Vi kan lage en fordeling av forskjellene mellom middeltallene og vi kan beregne standardavviket til fordelingen av forskjeller kalt standardfeilen til forskjellene. Skal vi finne forskjeller brukes hypotese-testing. Det er sjelden vi kjenner den sanne s2 Vi starter med en null hypotese som er en påstand om at det ikke er noen forskjell dvs. Man må på forhånd velge et sannsynlighetsnivå f. eks. p=0.05. Hvordan beregnes standardfeilen til en forskjell i middeltallene ? Når du har to middel fra uavhengige prøvene er variansen til forskjellene lik summen av variansene til de to prøves. Vi ønsker altså å trekke konklusjoner om hele populasjonen på grunnlag av en prøve. Vi beregner hvor sannsynlig det er at en forskjell så stor som den vi har funnet ville inntre/forekomme hvis det ikke var noen forskjell mellom middeltallene. Vi antar at det ikke er noen forskjell mellom middeltallene og etterpå ser vi på hvor sannsynlig det er at dette er sant. Det formuleres altså en null hypotese at det ikke er noen forskjell. Beregn sannsynligheten for at den forskjellen du ser er minst så stor som du den kan observere i din prøve hvis nullhypotesen er sann.Z-score - standard normalt avvik
En verdi av en observasjon x på abscissen i en normalfordeling kan beskrives i "antall standardavvik" som x er vekk fra middeltalletZ-score på 1.96 og 2.58 angir grensene på begge sider av populasjonsmiddelet og omfatter hhv. 95 % og 99 % av alle observasjonene. 50 % (0.67), 5% (1.96), 1% (2.58) og 0.1% (3.31). På samme måte som en observasjon kan omgjøres til z-score kan den omgjøres til t-score hvis vi har små prøver (<30).
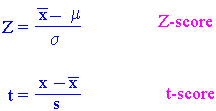
- 1. Ta din verdi og trekk den fra middeltallet. Hvis resultatet er positivt er den over gjennomsnittet. Er den negativ er den under gjennomsnittet.
- 2. Divider forskjellen på standardavviket. Den verdien du får forteller deg hvor mange standardavvik en score er over eller under gjennomsnittet.
Students t-test
En t-test brukes til å sammenligne om det er signifikant forskjell mellom to små prøver. F-testen brukes til å sammenligne variansen til to prøver. Et standard problem i biologisk forskning er å bestemme om det er en statistisk forskjell mellom middeltallet i to populasjoner. Observert signifikans er sannsynligheten for at en forskjell minst så stor som den observerte ville ha oppstått hvis middeltallene hadde vært like. W.S. Gosset skrev under navnet Student og skapte en familie av fordelinger som har en innebygget gjenkjennelse av begrensningene ved små prøvestørrelser. Student studerte fordelingen av t og fant at den var symmetrisk og formet som normalfordelingskurven og variansen var avhengig av antallet måledata n. Dette er koblet sammen med begrepet frihetsgrader. Forskjellen i middeltall divideres på standardfeilen til differansen.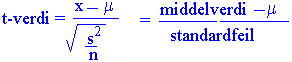
I en F-test sammenlignes variansen i to prøver. Har fått navn etter R. Fisher. F er beregnet slik at F er alltid større enn 1. Derfor må det velges slik at alltid telleren er større enn nevneren. Nullhypotesen for F antar at de to prøvene kommer fra samme normalfordelte populasjon og derved har samme varianse. Denne hypotesen beholdes eller forkastes.
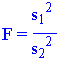
Chi-kvadrat test
Chikvadrattest brukes til å bestemme om det er signifikant forskjell mellom observert og forventet frekvens av to datasett. Bare frekvens-data kan analyseres med en chi-kvadrattest dvs. testen baserer seg på diskrete variable. Hvordan kan en null hypotese testes om to prosenter er like og at de to variablene er uavhengige ? Vi bruker antall observerte tilfeller som observerte frekvenser og forventet frekvens. Når vi ønsker å studere forskjellen mellom et sett observerte frekvenser brukes chi-kvadrat statistikk. For hver rute finnes: 1. Forskjellen mellom observert og forventet frekvens. 2. Divider kvadratet til forskjellen på forventet frekvens. Hver forskjell kalles residual (rest). Positiv residual indikerer flere tilfeller observert enn forventet fra null hypotesen. Negative residual indikerer færre observerte tilfeller enn forventet. Akkurat som for en t-statistikk beregnes nå hvor ofte du vil få en verdi for chi-kvadrat statistic som er minst så stor som den du observerer i din tabell hvis null hypotesen er sann. k2k2for virkelige tall er diskrete. Dette kan det tas hensyn til ved Yates korreksjon. Yates korreksjon for kontinuitet minsker den absolutte verdien for hver forskjell mellom observert og forventet verdi med 0.5. Chi-kvadratet modifiseres derved til:
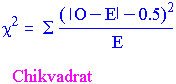
Kolonnens minimum forventet frekvens angir den minste forventede frekvens i tabellen. Man bør ikke bruke chi-kvadrat test hvis mer enn 20 % av rutene har forventet verdi mindre enn 5.
En Fisher eksakt test brukes istedet for chi-kvadrat hvis du har en 2x2 kontingenstabell og det er mindre enn 5 observasjoner bak hver rute. For tabeller med 2 rader og 2 kolonner (2x2) gjøres ofte en kalt Yates korreksjon. Denne er omdiskutert. I en chi-kvadrat test omdannes forventede prosenter til aktuelle tall. Multipliser forventet % med antall tilfeller i hver kategori. Antall frihetsgrader fås ved: substraher 1 fra antall rader substraher 1 fra antall kolonner multipliser disse to tallene med hverandre og du har tallet for antall frihetsgrader. hvor O er observert frekvens E er forventet frekvens Formelen angir summen av kvadratene av absolutte forskjeller mellom observert frekvens og forventet frekvens dividert på forventet frekvens.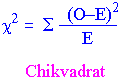
Korrelasjon
Hvis en variabel henger sammen med eller er assosiert med en annen er de positivt eller negativt korrelert. Selv om de er korrelert behøver ikke den ene være en funksjon av den andre. Det er sikkert mulig å finne en korrelasjon mellom antall lungekrefttilfeller og antall telefonsamtaler, men de har ingen sammenheng med hverandre. Man må skille mellom korrelasjon og regresjon. Regresjon- avhengighet mellom en avhengig variabel y og en uavhengig variabel x som forandres av den som utfører forsøket. Kan brukes til å forutsi en variabelverdi ut fra en en uavhengig variabel. Regresjon kalles å tilpasse en linje eller kurve til dataene. Korrelasjon- hverken x eller y er uavhengig variabel. Mye brukt er Pearson produkt-moment korrelasjon eller Spearman Rank ordnet korrelasjonskoeffisient. Er det ikke noen lineær sammenheng er r = 0. Er det en perfekt positiv sammenheng er r=+1. Betyr r=0 at det ikke er noen relasjon mellom de to variablene ? Nei, Pearson korrelasjonskoeffisient måler bare styrken av lineær sammenheng. Pearson korrealsjonskoeffisient bør bare brukes for lineære sammenhenger .Regresjon
Regresjon er en parametrisk statistisk metode som forutsetter at restene (residuals) av forskjellene mellom forventede og observerte verdier av de avhengige variablene er normalfordelte og med konstant variasjon. Det er forskjellige typer regresjon: - enkel lineær regresjon: en uavhengig variabel og avhengig variabel varierer lineært med den uavhengige. - multippel lineær regresjon: flere uavhengige variable og avhengig variabel varierer lineært med forandring i uavhengig variable.![]()
Lineær regresjon (minste kvadraters metode)
Den enkleste form for sammenheng mellom to variable er en rett linje. Hvis vi lager en grafisk fremstilling av x-verdier mot y-verdier kan vi få en tilnærmet rett linje, men ikke alle punktene faller på linjen. Vi ønsker derfor å kunne trekke den beste representative linjen gjennom punktskyen. Linjen er valt slik at kvadratet av summen av avvik for den beste linjen blir minst mulig. Tilpasning av data til en lineær funksjon med minste kvadraters metode er vanlig. Ligningen for den rette linje er angitt av en stigningskoeffisient og skjæringspunktet med y- aksen.![]()
Binomial fordeling
Man deler populasjonen i to deler og sier at den ene hendelsen skjer med sannsynlighet p og den andre tingen skjer med sansynligheten q og vi har p + q = 1. Myntkast er et eksempel på binomial fordeling. Sannsynligheten for å få en kron eventuelt mynt er p = 1/2. Hver prøve eller uttak er uavhengig av det foregående. Fordelingen ved å kaste 1 mynt er (p + q)1. Fordelingen ved å kaste 2 mynter er (p + q)2. Kastes 5 mynter er fordelingen (p + q)5 Hvis man regner ut dette blir det: p5 + 5 p4q + 10 p3q2 + 10 p2q3 + 5 pq4 + q5. Sannynligheten for å få 5 kron i dette siste tilfellet er p5 dvs (1/2)5 som er 1/32 som tilsvarer ca. 3 %. Sannsynligheten for å få 4 kron og 1 mynt er 5/32. Sannsynligheten P(r) for å få r av en sort og n-r av en annen sort er:
Poisson fordeling
Fordelingen har fått navn etter en fransk matematiker. Denne fordelingen er en spesialfordeling av den binomiale hvor sannsynligheten for å få det ene utfallet p er meget liten. p Vi har denne fordelingen når vi teller individer eller hendelser. Følgende forutsetninger må være tilstede: 1. Hvert individ eller hendelse må forekomme/skje tilfeldig i området/tid. 2. Hvert individ/hendelse forekommer uavhengig av de andre 3. Telletallet er funnet ved å telle antallet individer/hendelser av samme type som er tilstede i et gitt enhetsareal eller per tidsenhet. Dette blir eksempler på stokastiske eller tilfeldige prosesser. For Poisson-fordelingen er middeltallet lik variansen. Det betyr at standardavviket blir ± kvadratroten til telletallet. Hvis variansen er større enn middelet er det klumpingseffekter. 0! = 1 n! = n (n-1)(n-2)....2 1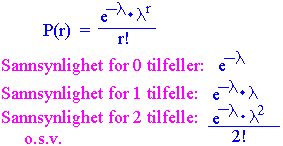
Variansanalyse
Student's t-test/Mann-Whitney analyserer data fra 2 grupper, men mange ganger skal 3 eller flere grupper sammenlignes. Problemet med å få en rekke t-tester unngås ved variansanalyse kalt ANOVA (analysis of variance) hvor alle sammenligningene gjøres i en test. ANOVA trenger en eller to faktorkolonner (indekserte data) og en datakolonne. To-veis ANOVA brukes hvis to eksperimentelle faktorer varierer for hver eksperimentell enhet. Kruskal-Wallis ANOVA brukes på rangeringer (ikke-parametrisk) ved at datasettet omdannes til en ordinal-skala (tilordninger). I prøvene er det 2 kilder til variasjon: 1. Variasjon rundt middelet innen prøven. 2. Variasjon mellom prøvene som skyldes differansen mellom midlene i populasjonen som prøvene kommer fra:Variabilitettotal=variabilitetinnen + variabilitetmellom. ANOVA deler opp den totale variasjon av et visst antall prøvene i deres enkelte komponenter. Det blir da enklere å arbeide med kvadratsummen SS (sum of squares), men i siste regneprosess omregnes SS til varianse ved å dividere på antall frihetsgrader. Hvis man anlyserer effekten av 2 variable på middeltallet har en 2-veis ANOVA. Er det bare 1 variabel er det 1-veis ANOVA.
SSmellom gruppene måler variasjonen til gjennomsnittsforskjellen mellom prøvegruppene. SSinnen gruppene (også kalt rest SS) måler den underliggende variasjon til alle de individuelle prøvene. Den totale SS angir total variasjon til observasjonene omkring middelet til alle observasjonene. MS gir to estimater på variasjonen i populasjonen. Hvilke forutsetninger gjelder? Hvordan kan man gjøre hypoteser om middeltallene ved å se på variasjon av observasjonene ? Hva er innen gruppen og mellom gruppene variasjon ? Hvordan gjøres en F-test og hvordan tolkes den ? Hver gruppe må være en tilfeldig prøve fra en normalfordelt populasjon og innen populasjonen må variansen i alle gruppene være like. I variansanalyse blir som tidligere nevnt den observerte variansen delt i to deler: variasjonen av observasjonen innen gruppen (omkring gruppens middel) og variasjon mellom gruppene. Du har et prøve middel for hver gruppe og du kan beregne hvordan disse midlene varierer. Først beregnes innen gruppen summen av kvadratene. Ta hver varianse og multipliser den med antall tilfeller i gruppen minus 1 og summer resultatet Neste trinn er å bestemme variasjonen i de individuelle gruppene "sum of squares" (SS) dividert på antall frihetsgrader. Antall frihetsgrader er antall resultater i hver gruppe minus 1. Resultatet angis som mean square (MS).Mellom gruppe variasjon
Først beregnes mellom gruppene SS ved å substrahere middelet av alle observasjonene fra hvert grupppe middel. Kvadrer forskjellene og multipliser med observasjonene i hver gruppe. Antall frihetsgrader beregnes ut fra antall grupper - 1. Mellom gruppene "mean square" (MS) beregnes ved å dividerer SS på antall frihetsgrader. F-ratio Det må nå estimere variasjonen innen poplasjonen: innen gruppen MS og mellom gruppene MS. Innen gruppen MS baserer seg på hvor mye observasjonene i hver gruppe varierer og mellom gruppe MS hvor mye gruppe midlene varierer. Hvis null hypotesen er sann bør disse to tallene være nær hverandre. Divideres den ene på den andre skal forholdet bli nær 1 Hvis F er ca lik 1 kan du konkludere med at det ikke er noen signifikant forskjellom mellom gruppene dvs. nullhypotesen beholdes. Hvis F er et stort tall kan du regne med at minst en av prøvene er fra en annen populasjon. For å bestemme hvilken gruppe som er forskjellig må du gjøre en multippel sammenligningstest (Bonferronit-test eller Student-Newman-Keuls test). Vi trenger nå å vite det observerte signifikansnivå. Hvorfor kan vi ikke bruke mange t-tester istedet ? Nei, fordi jo flere sammenligninger du gjør, desto mer sannynlig er det at du finner et par som er statistisk forskjellig selv om alle midlene er like i populasjonen. Til en-veis variansanalyse kan benyttes tukey-b multippel sammenligning. Hvis man har to variable får man en 2-veis analyse av variansen. ANOVA gir deg også mulighet for å finne interaksjonseffekter. Assosiasjoner sier noe om de to variablene er relatert Plotte data i en grafisk framstilling er den beste måten å se etter relasjoner og mønstere.Forsøks-design :Randomisert blokk-design
Hvis vi skal samle prøver fra et stort areal kan det være en underliggende systematisk kilde til variasjon som skyldes gradienter i omgivelsene. Slike gradienter kan være vind, drenering eller eksponering. Vi deler ved randomisert blokk-design forsøksenhetene inn i like mange blokker som vi har replikater/gjentak. Formålet er å få variasjonen innen blokkene så liten som mulig. Middelkvadratet "Mean square" (MS) er et annet mål på variansen-estimatet hvor man deler kvadratsummen SS på antall frihetsgrader. Dette gir MS varians estimat assosiert med variasjonen mellom behandlingsmidlene og variansen innen gruppene:MSError = SSError / d.f.
F = MStreatment/ MSError
Jo mindre error MS desto lettere er det å oppdage forskjeller. Antar at omgivelsesfaktorene innen blokken er relativt konstante og at maksimal heterogenitet i omgivelsesfaktorene er mellom blokkene dvs. vi antar at det er minimum variasjon innen blokken og maksimal variasjon mellom blokkene. Total SS kan reduseres ved å fjerne SS som skyldes varianse mellom blokkene.SStotal= SShovedeffekten + SSblokker + SSinnen blokken
Faktorielle eksperimenter
Faktorielle eksperimenter tillater separasjon og evaluering av interaksjoner mellom effektene av to eller flere faktorer i et eksperiment. F.eks. kan interaksjonen av faktor A ha forskjellig effekt i nærvær av faktor B enn uten B.Spredning (dispersion)
Sannsynlighetsregning kommer fra studiet av spill, og går ut på å kvantifisere sannsynligheten for at en spesiell hendelse skal skje. Sannsynlighetsskalaen går fra 0 (umulig) til 1. Myntkast er ofte brukt som eksempel. Det er hovedsakelig 3 måter objekter/ kan fordele seg på et gitt område: regulært, tilfeldig eller klumpet. Det er en indeks som kan beskrive spredningen: Er dette forholdet < 1 tyder det på regulær fordeling og man velger en binomial modell. Er forholdet = 1 tyder det på tilfeldig fordeling og vi velger Poisson fordeling. Er forholdet > 1 antyder det klumpet fordeling og vi velger negativ binomial fordeling. Forholdet mellom variansen og middelet kan standardiseres ved å multiplisere med antall observasjoner minus 1. En prøve med telledata som har liten varians indikerer et regulært mønster. Er det stor variasjon tyder det på klumpet, og tilfeldig spredning faller midt imellom. Variablene kan klassifiseres i forskjellige grupper basert på hvordan de er målt: nominal -(lat. ord) plassering av et individ i en gruppe f.eks. han eller hun. ordinal -(lat. orden) Inneholder en rangering f.eks. fra sjelden til vanlig 1-6 interval -måletall ratio Vi kan bruke regresjonsanalyse for å forutsi verdien for den avhengige variable basert på de uavhengige variable målt som interval eller ratio. Diskriminantanalyse brukes hvis den avhengige variable er en ordinal Faktor analyse I Clusteranalyse søkes det etter like grupper.Litteratur
- Brown, D. & Rothery, P.: Models in Biology. John Wiley & Sons 1993.
- Fowler, J. & Cohen, L.: Practial statistics for field biology. Open University Press 1990.
- Mead, R. & Curnow, R.N. Statistical methods in agriculture and experimental biology. Chapman and Hall 1983.
- Schefler, W.C. Statistics for the biological sciences. Addison-Wexley Publ.Comp 1979. SPSS/PC Base manual. SPSS Inc. 1988.