Laboratorieeksperimenter gir størst mulighet for kontroll av variable som kan påvirke resultatet. I felt kan det utføres småskalaeksperimenter, storskalaeksperimenter eller naturlige eksperimenter. Observasjonsstudier er en annen type undersøkelser som danner grunnlag for kunnskapsinnsamling og statistisk inferens ved bruk av naturen og naturlige eksperimenter som studieobjekt. I et observasjonsstudium kan man ikke manipulere variablene slik som i et eksperiment. Vanskeligheten med observasjonsstudier er svært mange uavhengige variable, og mulighet for konfundering (tredjevariabelfeil).
I all eksperimentdesign må det foretas en kost-nytte vurdering, vurdering av kostnader i tid og penger i gjennomføring av studiet eller eksperimentet. Innen medisin anvendes randomiserte dobbelt blind og placebokontrollerte forsøk.

Før man kan utføre et eksperiment må man ha en hypotese om et observert fenomen eller tilfelle, og fra hypotesen følger prediksjoner som kan bli testet i et eksperiment. En hypotese er et presist utsagn som angir forventet resultat, en forklaringsmodell som kan bli testet med data. Data er informasjon fra målinger av objektene man undersøker. I alle eksperimenter må det være flere kontrollgrupper.
Negative kontroller forventes ikke å gi noen forandring under forsøket.
Positive kontroller brukes for å se at forsøkssystemet responderer som forventet . Hvis man bruker et kjemisk stoff, må det være en egen kontroll for middelet som stoffet er løst i (formidlerkontroll).
En indre standard vil si å tilsette en kjent mengde stoff som man kan følge samtidig med stoffet man undersøker. En simulert kontroll, placebo, og imitert kontroll er andre eksempler. Hvis flere personer skal utføre samme type måling eller observasjon med personellet trenes og standardiseres.
Et pilotstudium med et lite antall eksperimentelle enheter kan brukes for å teste prosedyrer og metoder. Hvor mange replikater som skal inngå i forsøket avhenger av effektstørrelsen, det vil si hvor stor forskjell det er mellom sentrum eller gjennomsnitt i hver gruppe, samt gjenerell støy. Balansert design vil si at de forskjellige faktorvariablene må ha like mange replikater.
Man må klarlegge hvilke variable som skal inngå i forsøket og hvilke typer det er. Variablene kan være kontinuerlige (for eksempel lengde, tid) eller kategoriske (diskrete). Kategoriske variable har begrensning i antall mulige verdier.
Man må forsøke å identifisere uavhengige variable som varierer i bakgrunnen av eksperimentet og som kan gi konfundering. Man må dessuten undersøke om noen av variablene kovarierer. Hvilken type statistikk og statiske metoder man vil bruke må bestemmes på forhånd, og man undersøke forutsetningene for å kunne anvende disse. Målefeil og måleusikkerhet må estimeres. Måleutstyr må kalibreres. Innen vitenskap er målinger og registreringer beheftet med usikkerhet. Et stokastisk (tilfeldig) system inneholder tilfeldige prosesser og er til en viss grad ikke forutsigbart. Arter og metoder som inngår i forsøket må være meget nøye beskrevet. Hvor stor prøve man skal ta ut bestemmes ut fra måleusikkerhet og hva man forventer av forskjeller jfr. teststyrke beregnet ut fra sentral tendens.. Utvalg av prøver fra populasjonen må være tilfeldig.
Alle typer eksperimenter og observasjonsstudier må igjennom en etisk vurdering før de kan igangsettes. Regionale komitéer for medisinsk og helsefaglig forskningsetikk. Bruk av forsøksdyr fra tifotkreps til mer avanserte dyr krever spesiell tillatelse.
Statistiske sannsynlighetsfordelinger
Det finnes mange sannsynlighetstetthetsfordelinger. Feller for dem er at arealet (integralet) under sannsynlighetstetthetsfunksjonen blir lik 1. Det vil si arealet går fra 0-1 slik som sannsynligheter. Slike sannsynlighetstetthetsfunksjoner finnes for mange statiske fordelinger. De med kontinuerlige variable: normalfordelingen, lognormalfordelingen, Students t-fordeling, Kjikvadratfordelingen, Uniform fordeling, Betafordelingen, Gammafordelingen, Eksponentialfordelingen, Weibullfordelingen, Rayleigh-fordelingen, F-fordelingen, Cauchy-fordelingen, Gumbel-fordelingen,
De med diskrete eller diskontinuerlige variable: Poisson-fordelingen, Binomialfordelingen (myntkastfordelingen), Negativ binomialfordeling, Geometrisk fordeling,
Studiedesign og prøveuttak
En populasjon består av alle objekter av typen som det er mulig å undersøke. En prøve er en representativ undermengde av populasjonen.
Prøveuttaket fra en populasjon må være representativ, og man må bruke myntkast eller slumptall for å plukke ut hvem som skal inngå i henholdsvis kontroll- og behandlet gruppe. Når prøvestørrelsen (n) øker så blir den mer representativ for populasjonen. Med replikasjon og randomisering gjenspeiler prøven populasjonen. Hvert objekt i populasjonen må ha samme sannsynlighet for å bli tatt ut i prøven. Det er viktig å foreta frafallsanalyse av hvem ikke møter opp og eller hvem sier nei til å delta. Disse vil påvirke representativiteten til prøveuttaket.
Studiedesign angir hvordan data samles inn, og her må alle deler og forhold ved eksperimentet beskrives så nøye at det er mulig å reprodusere det. Den vitenskapelige metode baserer seg på at fra observasjon av et fenomen kan det lages en testbar hypotese som forklaringsmodell på fenomenet. I et eksperiment er det en avhengig responsvariabel, og en eller flere forklaringsvariabler som eksperimentator kan variere. Behandlingen gis til eksperimentelle enheter. Et godt eksperiment må være basert på gode kontrollgrupper, randomisering ved uttak av eksperimentelle enheter og behandlinger, og et nødvendig antall replikater (gjentak). En historisk kontroll kan være estimater fra et tidligere studium. Fullstendig randomisert design og randomisert blokkdesign er eksempler på eksperimentelt studiedesign som sikrer randomisering. I et balansert design er det flere grupper som sammenlignes, og hver gruppe har samme antall subjekter eller objekter.
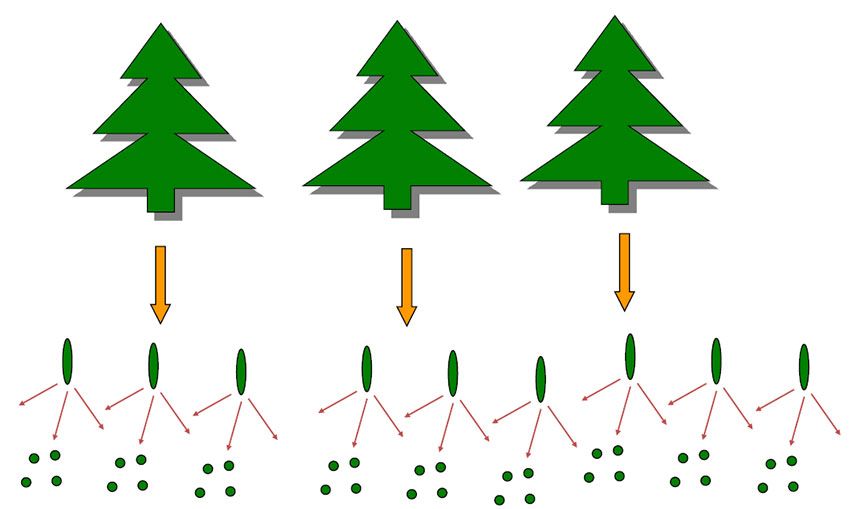
Romlig pseudoreplikasjon. Gjentatte prøver fra her tre trær er ikke uavhengige, og antall frihetsgrader (df) er lik n=3, selv om man har tatt ut 36 prøver. Dessuten hvis disse tre trærne står på samme lokalitet, så er heller ikke disse uavhengige av hverandre, og man ender da opp med n=1, altså, df=1. Prøver tatt ut etter hverandre i tid er heller ikke uavhengige, og vi har i dette tilfellet tidspseudoreplikasjon. Uavhengighe prøver og homogen varians er viktige forutsetninger i studiedesign.
Den andre typen pseudoreplikasjon er tidsseriedata som gir tidsavhengig pseudoreplikasjon. Tidsseriedata er ikke uavhengige, de ser seriekorrelerte eler autokorrelerte. Bruk av pseudoreplikerte data og betrakte dem som uavhengige er en vanlig feil i design av vitenskapelige studier ("Why most published research findings are false)"
Fra prøveresultatet kan man gjøre statistisk inferens , trekke slutninger om populasjonen, enten å estimere konfidensintervall eller å teste hypoteser basert på p-verdier. Vi kjenner ikke de sanne parameterverdiene for populasjonen, men ønsker å lage et estimat av dem basert på prøven.
Et punktestimat har en feilkilde på begge sider. 95% konfidensintervall vil si at 95% av målingene vil være innenfor punktestimat ±1.96∙standardfeilen (SE). Type I-feil α hvor man forkaster en sann nullhypotese.
Nullhypotesen H0 er lik:
\(H_0: \mu_1 = \mu_2\)
Sannsynligheten P for å begå minst en type I feil i N-tester er gitt ved:
\(P=1 - \left( 1- \alpha\right)^2\)
Type II-feil β hvor man begår feil og aksepterer en falsk (usann) nullhypotese.
|
|
Aksepter H0 |
Forkast H0 |
|
H0 sann |
OK |
Type I feil |
|
H0 falsk |
Type II feil |
OK |
Type I feil vil si at nullhypotesen forkastes selv om den er sann. Signifikansnivå alfa (α) angir sannsynlighet for å begå type I-feil, α=0.05 vil si 5% sannsynlighet for type I-feil. p-verdi og α er ikke det samme. Hvis α settes til en meget liten verdi e.g. α=0.001 så blir det vanskelig å forkaste nullhypotesen. Da kan man begå type II-feil, dvs. beholder nullparameter som ikke er sann og nullhypotesen blir ikke forkastet. Sannsynligheten for type II feil kalles beta (β), og vanligvis er β = 0.1-0.2. Sannsynligheten for at nullhypotesen forkastes når den er falsk kalles teststyrke lik 1 -β.
Teststyrken (1- β) til en hypotesetest er sannsynligheten for at man korrekt forkaster en falsk nullhypotese, hvor β er sannsynligheten for å gjøre en type II feil.
Hvis β=0.2 blir teststyrken 0.8 som betyr at det er 80% sannsynlig for at en falsk nullparameter og nullhypotese vil bli forkastet. I longitudinelle studier og ved romlig prøveuttak i et forsøksfelt er pseudoreplikasjon et problem, man har ikke uavhengige prøver.
Miksete effektmodeller gir mulighet til å ta hånd om pseudoreplikerte data. Det er mange kritiske bemerkninger til anvendelse av p=0.05 statistikk, i 1 av 20 tilfeller tar man dessuten feil, og man bør i stedet angi effektstørrelser og konfidensintervall. Det samme gjelder hypotesetesting hvor man i utgangspunktet sier at man ikke har noe forhåndskunnskap, i motsetning til Bayesiansk statistikk hvor man aktivt benytter forhåndskunnskap (prior) om fenomenet man undersøker, for bedre å kunne angi og oppdatere en posterior sannsynlighet. p=0.05 statistikk kan også resultere i publiseringsskjevhet.
Spesielt innen medisin og epidemiologi er falske positiver eller falske negativer et stort problem. Med Bayes formel kan man vise at ved masseundersøkelse ("screening") av store befolkningsgrupper for en relativt sjelden sykdom med en test som ikke er 100% sikker, vil resultere i mange falske positiver og bidra til å sykeliggjøre en hel befolkning. Dessuten har det vist seg at mange publiserte eksperimenter ikke lar seg reprodusere. Derfor er det viktig at datasett gjøres tilgjengelige for alle, og at det anvendes metoder som er tilgjengelige for flere, slik at resultatene kan etterprøves. Det finnes en rekke statistiske modeller som kan anvendes i den statistiske analysen av datasett fra eksperimentene hvor en forventning eller responsvariabel (avhengig variabel) er forklart av en eller flere forklaringsvariable (uavhengige variable) med tilhørende parameterverdier og standardfeil: Lineære modeller (en kombinasjon av regresjons- og variansanalyse), generaliserte lineære modeller med linkfunksjoner (Poissonfordeling, Binomial fordeling (logit, logaritmen til odds)), miksete eller blandete effektmodeller, og generaliserte additive modeller. Odds-ratio og kontingenstabeller. Overlevelsesanalyse. Ekstremverditeori. Simpsons paradoks. I prinsipalkomponentanalyse kan man analysere datasett hvor det ikke kan defineres avhengige eller uavhengige variable.
I en Poisson-regresjonsmodell er gjennomsnittet lik varians. Hvis varians er større enn forventet og større enn gjennomsnittet så har vi overdispersjon.
For å kunne gjøre et ekte eksperiment må vi ha et system hvor det er mulig å variere behandlingsfaktorer uavhengig av hverandre, det vil si at systemet må kunne manipuleres, og hvor vi kan sikre oss mot tilfeldige og systematiske feil ved hjelp av replikering, randomisering og blokking. I tillegg må det gjøres etiske betraktninger vedrørende eksperimentet.
Blokker og blokkdesign gir mulighet til å ta hånd om gradienter i eksperimentsystemet, hvor alle de eksperimentelle enhetene forkommer innen en blokk. I tillegg bør vi ha undersøkt på forhånd gjennom datasimulering eller tilsvarende hvorvidt designet vårt har tilstrekkelig styrke til å kunne påvise en effektstørrelse av et omfang som vi på forhånd oppfatter som biologisk relevant. Uavhengighet og homogen varians er viktig innen eksperimentdesign. Mennesket har dårlige evner til å vurdere tilfeldighet. Myntkast, terningkast eller slumptall kan anvendes for å få et mest mulig representativt prøveutvalg fra populasjonen.
Før man gjør statistisk analyse av resultatene må de visualiseres for å få oversikt, for eksempel punktskyplot med lineær eller ikke-lineær regresjon, stolpediagram, boksplot, eller mosaikkplot.
Et boksplot viser fordelingen av et utvalg fra en stokastisk variabel. Den rektangulære boksen omfatter verdier fra første kvartil til tredje kvartil, interkvartilområdet = 25% - 75% persentil, mens den horisontale svarte streken i boksen er midtverdien (medianen= = 50% persentil). Fra boksen går det ut to vertikale streker som danner et indre «gjerde». Strekene omfatter ekstremene av de verdiene som ligger innenfor1.5 ganger interkvartilområdet. Verdier som ligger utenfor «gjerdet» og som ofte kalles potensielle «utliggere», er vist som åpne sirkler. . For en normalfordeling vil medianen (midtverdien) ligge omtrent midt i boksen, og værhårene går omtrent like langt ut på begge sider av boksen.
Ved anvendelse av statistiske modeller må man undersøke om forutsetningene er oppfylt før man tar i bruk modellen. Ved modelltesting velger man å bruke den enkleste modellen som inneholder færrest forklaringsvariable (parsimoni, Occams prinsipp), valgt ved e.g. Akaikes informasjonskriterium (AIC) hvor det er innalgt en "straff" hvis modellen inneholder mange forklaringsvariable, eller Bayesiansk informasjonskriterium (BIC).
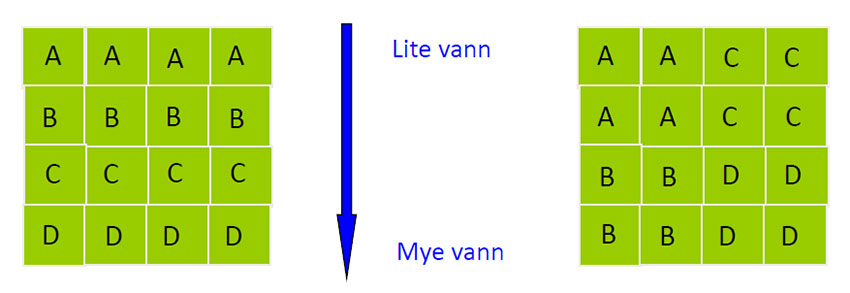
Hvis man har fire eksperimentelle enheter A, B, C og D og det er gradienter av en faktor, kan man i blokkdesign organisere alle de eksperimentelle enhetene i en blokk, og la blokk være en av variablene i modellen. I den statistiske analysen kan man derved finne om blokk er en signifikant faktor.
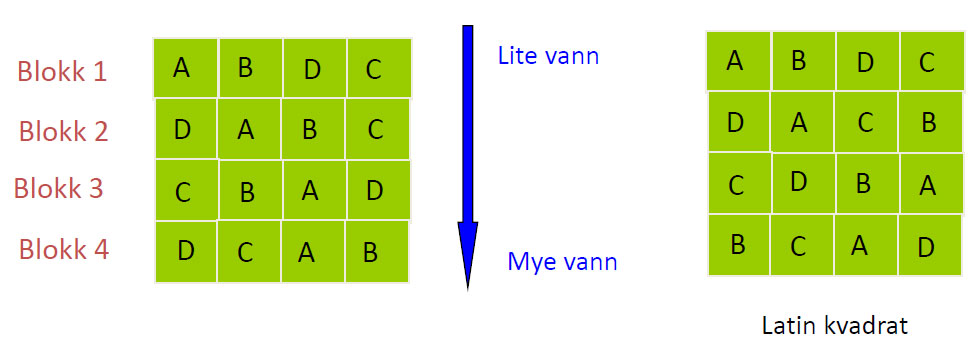
Blokkdsign hvor de eksperimentelle enhetene er organisert i fire blokker. I et latinkvadrat design er heller ikke plasseringen innen blokkene like.
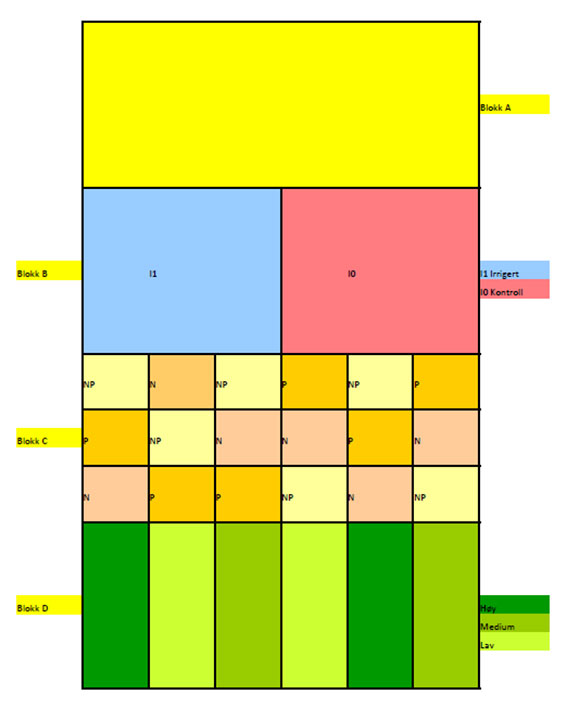
Splitplot design i et forsøksfelt. Biostatistikeren RA Fisher arbeidet ved Rothamsted Experimental Station viste at det ofte forekom dårlig eksperimentdesign. Figuren viser et studiedesign for et forsøk med å studere biomasseproduksjon med variablene: Irrigasjon - Ikke irrigasjon, tre forskjellige gjødselkombinasjoner N (bare nitrogen), P (bare fosfor) og NP (nitrogen og fosfor) , alle i tre forskjellige konsentrasjoner; Høy-Medium-Lav, organisert i fire blokker. Blokkdesignet er organisert i forsøksfeltet slik at med rimelig grad av letthet kan manipulere de forskjellige variablene som inngår i eksperimentet. Dette er også et eksempel på et faktorielt design hvor man innen et eksperiment varierer flere variable samtidig, noe som i tillegg til å se virkningen av hver enkelt variabel også gir mulighet til å undersøke om det er interaksjon mellom variablene. Og som alltid: korrelasjon betyr ikke årsakssammenheng, og selv om noe er statistisk signifikant behøver det ikke være biologisk interessant.
Den vitenskapelige metode og statistisk inferens
Økologiske systemer er komplekse og det er ikke mulig å registrere alle variable. Hva skal måles og hvordan måle ? Det er metodiske regler som rettleder forskningen, alt basert på den vitenskapelige metode. Den vitenskapelige metode gjør det mulig å skille mellom hypoteser basert på observasjoner med tilhørende prediksjoner. Deduksjon vil si å gå fra det generelle tilfelle til det spesielle. Induksjon (Francis Bacon 1561-1626) vil si å gå fra det spesielle til det generelle, det vil si man starter med en observasjon og utvikler en hypotese som forklarer observasjonen. Den hypotetisk deduktive metode ble videreutviklet av Newton basert på flere arbeidshypoteser. I den hypotetisk deduktive metode behøver man ikke bare utvikle hypoteser som er basert på data og observasjoner.
Data møter modell, og modell møter data
En modell er en abstrakt beskrivelse av observasjoner og sammenheng mellom variable.
Pr {data|modell} betyr sannsynligheten (Pr) gitt modellen, hvordan passer data til modellen. Pr{modell|data} betyr sannsynligheten gitt data, hvordan passer modellen til data. Vi må finne et mål på sannsynligheten av de observerte data gitt at modellen er sann. Likelihood-estimering brukes til å finne parametre i en gitt modell som passer best til data. Ved likelihood-estimering er data kjent, men hypotesen ukjent. Ved sannsynlighets-estimering er sannsynlighet kjent, men data ukjent. Likelihood er proporsjonal med sannsynligheten p.
Modeller
Modeller brukes for å vurdere hypotesen, forklare data og prediktere (fremtidsbeskrive). En modell gir en forenklet grafisk eller matematisk framstilling, og og gir en sentral beskrivelse av en økologisk prosess. Modellen hjelper til med å identifisere parametre som må måles, og gir hjelp til å bestemme hvilke av parametrene som er viktigst. Modellen er et vitenskapelig verktøy, og man må validere forutsetningene for modellen og validere selve modellen. Modellen er ikke en hypotese, og man må skille mellom hypotese og modell. Bruk av forskjellige modeller til å beskrive samme fenomen er nyttig, og gir økt forståelse av prosesser og mønstre i det naturlige systemet. Jo flere faktorer eller variable modellen inneholder desto bedre tilpasning gir den til data, men modellen skal ikke bli like kompleks som naturen selv. En for enkel modell utelater viktige variable. En for kompleks modell er uoversiktelig, og det er som regel ikke nok informasjon i datasettet til å bestemme parameterverdiene βn med tilstrekkelig nøyaktighet. Modellen kan brukes til planlegging av eksperimenter og kan være hjelp til å identifisere konfunderte variable. En vitenskapelig modell gir en beskrivelse av hvordan naturen fungerer og predikterer oppførselen til uavhengige og avhengige variable.
En statistisk modell beskriver relasjoner mellom variable og er ofte en regresjonsmodell. En statistisk modell predikterer responsen som en forklaringsvariabel gir. En dynamisk modell viser hvordan responsen endrer seg over tid. Deterministiske modeller har ingen innebygd usikkerhetsfaktor, og ingen av parametrene følger en sannsynlighetsfordeling. Modellen kan ofte bare beskrive gjennomsnitts- eller modalverdi til parametrene.
I stokastiske modeller er noen av parametrene beheftet med usikkerhet som kan beskrives med en sannsynlighetsfordeling. I en deterministisk modell vil samme startverdi gi samme resultat. En stokastisk modell vil gi forskjellig resultat avhengig av verdien til den tilfeldige stokastiske variabel. Man trenger derfor å vite noe om stokastisiteten til data.
En økologisk modell beskriver en prosess. For eksempel i et studium av populasjoner er det usikkerhet tilknyttet hver av prosessene fødselsrate, dødsrate og migrasjonsrate.
Naturen følger ofte ikke normalfordelingen (Gaussfordelingen), og man trenger derfor andre sannsynlighetsfordelinger. Imidlertid vil gjennomsnitt av andre ikke-normalfordelte sannsynlighetsfordelinger ofte følge normalfordelingen, ifølge sentralgrenseteoremet. En kvantitativ modell gir en numerisk prediksjon av responsen. Kvalitative modeller gir en generell beskrivelse av responsen, for eksempel respons/ikke respons på en variabel. Nestede modeller øker kompleksiteten slik at den mer komplekse modellen inneholder den foregående modellen som et spesialtilfelle med faste parameterverdier. Miksete eller blandete effektmodeller tar hånd om pseudoreplikasjoner og deler variable inn i forskjellige typer.
Statistiske metoder
I tillegg til tradisjonelle parametriske metoder som forutsetter normalfordeling, ikke-parametriske metoder for ikke-normalfordeling, ofte rangeringstester for analyse av data, er det mulig å benytte Bayesianske metoder eller Monte-Carlo-metoder. Alle er basert på randomiserte (stokastiske) og uavhengige data. Parametrisk analyse bygger på forutsetninger om en sannsynlighetsfunksjon for fordeling av gjennomsnittsverdien μ og variansen σ2, og den tradisjonelle klassiske måten å gjøre statistisk analyse og inferens. Parametriske metoder gir et mål på sannsynligheten for nullhypotesen, men angir ikke noen verdi for sannsynligheten for den alternative hypotesen. Ikke-parametriske tester er en form for Monte-Carlo-analyse basert på rangeringer. Monte-Carlo-metoder bruker slumptall til å generere data og teste modeller. En slumptallsgenerator er nødvendig for å kunne simulere naturlige fenomener. Før man starter et prosjekt som innebærer parameterestimering i en modell kan man forsøke å estimere parametre ved å simulere data ved hjelp av Monte-Carlo-teknikker. Bootstrap er eksempel på en Monte-Carlo-metode med randomisert skyfling og resampling av data.
Bayesianske metoder
Det er sjelden man ikke har noe forhåndskunnskap ved starten av en analyse, i motsetning til en null-hypotesestrategi (frekventistmetode). I Bayesiansk metoder benytter man empirisk forhåndskunnskap basert på en ”prior” lik Pr{hypotese}. Prior bestemmes før man utfører eksperimentet, og det er en pågående diskusjon mellom frekventister og Bayesianere om valget av denne prior. Ankepunktet er at prior er bestemt på forhånd, slik at man ikke er uhildet nøytral på forhånd, som frekventistene hevder man bør være. Imidlertid har moderne datateknologi gjort det mulig å velge en nøytral uinformativ prior. Uinformativ prior sier at vi allikevel ikke har noen forhåndskunnskap om prior. Likelihood-estimering danner grunnlag for Bayesiansk analyse og gir mulighet til å bestemme konfidensintervall for parameterestimater
I Bayes teorem finner man en betinget posterior sannsynlighetsfordeling, sannsynligheten for hypotesen gitt data, Pr{hypotese|data}, ofte bare kalt posterior, eller posterior sannsynlighetsfordeling
\(\displaystyle\text{posterior} =Pr\left[hypotese|data\right] =\frac{Pr\left[hypotese\right]\cdot Pr\left[data|hypotese\right]}{Pr\left[data\right]}\)
Pr{data|hypotese} kalles likelihood til data, det vil sannsynligheten for å få et sett data gitt hypotesen. Pr{data} er en normaliseringskonstant som sørger for at posterior blir liggende innen området [0,1]. Både gjennomsnitt og varians har en prior sannsynlighetsfordeling. Alle variable følger en sannsynlighetsfordeling med verdier, men istedet for å se på enkeltverdier betrakter vi hele sannsynlighetsfordelingen som sådan med en gjetning om hvor parameterverdiene må befinne seg med størst sannsynlighet, en forhåndssannsynlighetsfordeling, en prior sannsynlighetsfordeling. De observerte dataene vil følge en likelihood sannsynlighetsfordeling. Likelihood og prior kombineres og danner utgangsmateriale for en posterior sannsynlighetsfordeling som viser hvilke parameterverdier som gir størst sannsynlighet for å en observert verdi. Forhåndsgjetningen med prior sannsynlighetsfordelingen er mer spredd utover sammenlignet med likelihoodfordelingen som er basert på datasettet vi har. En presisjon tau (τ) brukes som estimat av varians (τ=1/varians) og denne kan følge invers gammafordeling. Deretter beregnes likelihood og maksimum likelihood. Bayesianske metoder ender i en sannsynlighetsfordeling i stedet for en fast p-verdi. Straks posterior er estimert kan denne brukes til å finne en bedre prior, og så gjentas prosessen hvor den nye prior gir et bedre estimat av posterior sannsynlighetsfordeling, og dette gjøres i en rekke gjentakelser (iterasjoner). Er det noe datamaskiner er gode til er å gjenta den samme prosessen millioner av ganger. Betafordelingen er også mye brukt innen Bayesianske metoder.
Utplukking av søppelpost (”spam”) fra E-post-leseren er basert på Bayesiansk statistikk og forhåndskunnskap (prior) om hva søppelpost pleier å inneholde av ord, tall og vendinger.
Bayesiansk multippel imputering (Bayesian multiple imputation) kombinert med maksimum likelikelihood er en metode for erstatte manglende verdier i et datasett.
Monte Carlo-metoder og Markov-kjeder
Monte Carlo-metoder bruker pseudoslumptall til å generere og lage simulerte datasett og teste modeller. Før man starter et prosjekt som innebærer parameterestimering i en modell kan man forsøke å estimere parametre ved å simulere data ved hjelp av Monte Carlo-teknikker. For eksempel ved å plukke ut hundretusenvis slumptall fra den uniforme fordelingen og klassifisere og fordele disse. Se for eksempel Monte Carlo metode for å estimere verdien av pi (π). Markovkjede Monte Carlo teknikker (MCMC) kombinerer Markov-kjeder og Monte Carlo og kan bli benyttet til å bestemme formen på posterior sannsynlighetsfordeling i Bayesiansk statistikk. Monte Carlo delen er å trekke tilfeldig fra et sannsynlighetsrom, og man lager derved sin egen Markovkjede. Markovkjeder, oppkalt etter Endrey Markov, er en kjede av uavhengige hendelser, men hvor hver hendelse ikke er påvirket av hva som har skjedd tidligere, den er uten "hukommelse" om tidliger tilstander. En Markovkjede kan være kontinuerlig eller gå i diskrete trinn, enten i tid eller rom. I kjeden fortid - nårtid - fremtid er man bare interessert i trinnet nå til neste trinn i kjeden. Imidlertid, hvis man har en transisjonsmatrise med sannsynligheter for de forskjellige tilstandene i kjeden så kan men for et par med tilstander finne hvilke av disse to som sannsynligvis passer best med datasettet, dette kan nå gjentas inntil kjeden konvergerer. Sannsynligheten qij i transisjonsmatrisen Q angir sannsynligheten for å gå fra tilstand i, Si , i populasjonen til tilstand j, Sj. I transisjonsmatrisen Q angir radene hvilken tilstand i et tilstandspar du beveger deg fra og kolonnne hvilken tilstand du beveger deg til. Summen av sannsynlighetene i en rad er lik 1.
\(P\left(S_{n+1}|S_n=i\right)=q_{ij}\)
For eksempel en Markovkjede med fire tilstander S1, S2, S3 og S4 , hvor sannsynlighetene qij i transisjonsmatrisen angir sannsynligheten for overgang fra en tilstand til en annen.
\(\displaystyle Q=\begin{pmatrix}S_1&S_2&S_3&S_4\\ q_{11}&q_{12}&q_{13}&q_{14} \\ q_{21}&q_{22}&q_{23}&q_{24} \\ q_{31}&q_{32}&q_{33}&q_{34} \\ q_{41}&q_{42}&q_{43}&q_{44} \\ \end{pmatrix} \begin{pmatrix} \text{Til}\\ S_1\\S_2\\S_3\\S_4 \end{pmatrix}\)
Transisjonsmatrise som viser sannsynlighetene qij fra tilstand S1, S2, S3 og S4 i radvektroen til tilstand til tilstand S1, S2, S3 og S4 i kolonnevektoren.
Hvis man tar radvektoren for tilstander \(\overrightarrow S\)og multipliserer denne med Q så får man fordeling av tilstander ved tid n+1.
\(\overrightarrow S\cdot Q\)
Vil man ha fordelingen av tilstander ved tid n+2 , osv.
\(\overrightarrow S\cdot Q^2\)
Kan man løse disse og finne en unik stasjonær løsning, det vil si hvor rekken konvergerer, det vil si
\(\overrightarrow S\cdot Q=\overrightarrow S\)
Se analogien med egenvektor· egenverdi er lik egenvektoren.
Metropolis-Hastings algoritmen , oppkalt etter Nicholas Metropolis og KW Hastings, er en MCMC-algoritme for å lage en sekvens av tilfeldige prøveuttak eller tilstander fra en multidimensjonal sannsynlighetsfordeling. Metropolisalgoritmen ble brukt blant annet i simuleringen og utviklingen av Teller-Ulam hydrogenbomben.
Bootstrap
Bootstrap henspiller på gamle beksomstøvler hvor man bak på støvelen hadde en lærhempe hvor man kunne henge opp støvelen til tørk. Her henspiller det på å løfte seg selv opp etter støvelhempel. Bootstrap er en er eksempel på endataintensiv iterasjonsmetode-metode med randomisert skyfling og resampling av data. Man anvender det datasettet man har ved titusenvis av ganger plukke gjentatte tilfeldige data ut fra det samme datasettet (interasjoner) ,og ut fra disse finne en statistisk sannsynlighetsfordeling som kan brukes til å estimere konfidensintervall for parameterverdier.
Klyngeanalyse
Klyngeanalyse er en metode for å gruppere observasjoner som har like egenskaper. Det finnes både hierarkiske og ikke-hierarkisme metoder. Ut fra sentrum i en sentroide kan man finne et optimalt antall centroider eller klynger, for eksempel med K-means clustering.
Lineære generaliserte modeller
En multippel regresjonsmodell er av følgende type hvor xi er forklaringsvariable (prediktorer, uavhengige variabler) , y er responsvariabel (avhengig variabel), βi er parameterverdier med tilhørende standardfeil i modellen som vi ønsker å bestemme, β0 er interceptverdien. Epsiloen (ε) er feil (støy) i modellen, og som kan være normalfordelt, ~ betyr modellert av. I statistikkprogrammer finner man parameterverdiene i en koeffisienttabell, en tabell med parameterverdiene i modellen. Koeffisientene er beregnet ut fra en referanse, en av variablene blir valgt som referanse i modellen, angitt som interceptverdien. Fra modellen kan man finne signifikante variable og foreta modellseleksjon, for eksempel basert på AIC-verdier (Akaikes informasjonskriterium). Med hjelp av koeffisientene kan man finne ut hvor mye y endrer seg hvis man øker en av variablene xi med 1.
I glm med normalfordeling:
\(\displaystyle X \sim N(\mu, \sigma ^2)\)
hvor X kan være forklaringsvariable xi har vi forventning for responsvariabel y:
\(y \sim \beta_0 + \beta_1x_1 +\beta_2x_2+\beta_3x_3+,\dotsc, \beta_nx_1 + \epsilon \)
Hva betyr parameterestimatene βi ? Vi kan la variabel x1 øke med 1 i et intervall [a,b=a+1]
\(\displaystyle\mu_a= \beta_0 + \beta_ 1x_1+ \beta_2 x_ 2+ \dots + \beta_n x_n\)
\(\displaystyle\mu_b= \beta_0 + \beta_ 1(x_1 + 1)+ \beta_2 x_ 2+ \dots + \beta_n x_n\)
\(\displaystyle\mu_b - \mu_a= \beta_1\)
Vi ser at parameterverdien angir forandring i forventet verdi av responsvariabel når forklaringsvariabel x1 øker med 1. Tilsvarende for de andre forklaringsvariable (uavhengige variable) xi. Fortegeet på βi viser om responsvariabel stiger eller synker med økning av variabelen med 1.
En Poisson-modell er av følgende type med den naturlige logaritmen til responsvariabel:
\(\displaystyle\ln\left(y\right)\sim \beta_0 + \beta_1x_1 +\beta_2x_2+\beta_3x_3+,\dotsc, \beta_nx_1 \)
Koeffisientene i Poisson-moddel blir uttrykt i enheten naturlige logaritmer (ln)
En logistisk modell brukes for binære utkomme (binomisk modell) hvor logit p er lik logaritmen til odds:
\(\displaystyle logit \;p=ln\left(odds\right)=ln\left(\frac{p}{1-p}\right)\sim \beta_0 + \beta_1x_1 +\beta_2x_2+\beta_3x_3+,\dotsc, \beta_nx_1 \)
Skal man estimere sannsynligheten p i en logistisk modell benytter man eksponentialfunksjonen på begge sider av likhetstegnet og regner ut. Koeffisientene i den logistiske modellen, logistisk regresjon, blir uttrykt i enhetene naturlige logaritmer til odds, ln(odds).
\(\displaystyle p=\frac{e^{\beta_0 + \beta_1x_1 +\beta_2x_2+\beta_3x_3+,\dotsc, \beta_nx_1 }}{\left(1+ e^{\beta_0 + \beta_1x_1 +\beta_2x_2+\beta_3x_3+,\dotsc, \beta_nx_1}\right)}\)
På samme måte som man bruker minste kvadraters metode hvor summen av de kvadrerte avvikene (residulane) gjøres minst mulig, så kan man bruke metoden for maksimum likelihood for å finne parameterverdiene som gir størst sannsynlighet for å få de dataene vi har fått. Det vil si at vi kjenner ikke sannsynligheten på forhånd, men estimerer den ut fra datasettet vi har skaffet oss. Ved maksimum likelihoodestimering estimeres parametrene slik Vi har en likelihoodfunksjon L(β) og devianse er forskjellen mellom -2∙logL (minus 2 ganger logaritmen likelihood) og den maksimale modellen.
Prinsipalkomponentanalyse (PCA)
Multidimensjonal skalering og reduksjon av antall dimensjoner. Hvis man ikke kan definere variable i kategoriene avhengig og uavhenge variable i multippel regresjon, men man har mange målte variable er prinsipalkomponentanalyse, en ordinasjonsmetode, meget anvendelig. Siden variablene har forskjellige måleenheter og størrelser så må de vektes før analysen kan fortas. Den totale variasjonen i datasettet deles i et prinsipalkomponentplot, med prinsipalkomponent 1 (PCA1) som forklarer mest variasjon ortogonalt på prinsipalkomponent 2 (PCA2) som forklarer den gjenværende variasjonen. På aksene er det vektede og veide summer av alle variablene i regresjonen. De vektede variabelsummene angis som punkter i forhold til de to aksene. Man projiserer den totale variasjonen, variansen, fra det n-dimensjonale vektorrommet ned i et todimensjonalt plan. Retningsvektorer til punktskyene i PCA-ordinasjonen viser hvor mye variablen påvirker variasjonen, og i hvilken retning. Forskjeller mellom punkter kan måles som Euklidsk avstand.
Observasjon og vurdering
Kahneman & Co sin siste bok Støy. Når dømmekraften svikter viser hvor skremmende stor spredning det generelt er i vurderinger som foretas på samme tilfellet eller objekt, og det gjelder innen alle samfunnsområder hvor det foretas beslutninger: rettsvesen, medisin, ansettelser, prestasjoner , eksamensbedømmelser osv. Det er krevende å gjøre subjektive vurderinger hvis det ikke finnes objektive og etterprøvbare kriterier for bedømmelsen. Hva er kunnskapsgrunnlaget for vurderingen. Tilfeldig spredning, variabilitet, støy, presisjonsskjevhet, situasjonsstøy, intrapersonlig støy og systematiske avvik påvirker konklusjonen. Hvis avgjørelsen tas av en gruppe det skje sosial påvirkning. Ofte kan man observere at flere uavhengige vurderinger av samme kasus kan gi lite samsvar i diagnose. Tid på døgnet, om man er i godt eller dårlig humør, om man er trett, blåøyd eller lettlurt medvirker i konklusjonen. Resulterer også i forskjellige behandlingsforslag, for eksempel innen psykiatri. En av Kahnemanns konklusjoner for å redusere støy og oppnå den mest «treffisikre» og «beste» resultat oppnår man ved å ta gjennomsnitt av mange uavhengige vurderinger. I noen tilfeller kan AI, dyplæring og algoritmer foreta "bedre" avgjørelser.
\(\displaystyle MSE= \frac{1}{n}\sum _{i=1}^{n}(X_i- \overline{X})^2\)
Gjennomsnitts eller midlere kvadrerte avvik (MSE) er en estimator som baserer seg på summen av kvadrerte avvik mellom estimert gjennomsnittsverdi og de aktuelle verdiene (Xi) dividert på antall observerte verdier (n).
I sin første bok: Thinking fast and slow (2011) viste den israelske psykologen Daniel Kahnemann hvor notorisk dårlige vi er til å vurdere sannsynligheter. Kahnemann introduserte begrepene System 1 og 2 tenking. System 1 for «ryggmargsreflekstenking» basert på tidligere erfaring, et følelsessystem og som evolusjonen har utviklet for å kunne ta raske instinktmessige avgjørelser. System 2 tenking er mer sakte og basert på mer nøye vurderinger og vektinger pro-kontra basert på logikk og eksakt kunnskap.
Kappastatistikk
Kappastatistikk (Cohens kappa) kan anvendes for å beskrive samsvar mellom uavhengige vurderinger når «fasiten» ikke er kjent.
Kappa (κ) blir lik 1 for komplett samsvar, lik 0 for bare tilfeldigheter, og mindre enn 0 hvor samsvaret er dårligere enn forventet ut fra ren tilfeldighet.
Kappa (κ) blir lik 1 for komplett samsvar, lik 0 for bare tilfeldigheter, og mindre enn 0 hvor samsvaret er dårligere enn forventet ut fra ren tilfeldighet.
Navn etter den amerikanske psykologen Jacob Cohen (1923-1998) som også arbeidet med temaer som teststyrke og effektstørrelser.
Po er relativ observert enighet pg pe er den hypotetiske sannsynligheten for enighet basert på de observerte data.
\(\displaystyle \kappa = \frac{p_o - p_e}{1-p_e}\)
Et alternativ er Gwets kappa.
Cohen Jacob: A coefficient of agreement for nominal scales, Educational and Psychological Measurement, 20 (1) (1960) 37–46, doi:10.1177/001316446002000104
Gwet K: Computing inter-rater reliability in the presence of high agreement. British Journal of Mathematical & Statistical Methodology, 61(1)(2008), 29-48. doi:10.1348/000711006×126600
Kahneman, D, Sibony O & Sunstein CR: Støy. Når dømmekraften svikter (Noise. A flaw in human judgment). Pax Forlag 2021.